K-means Clustering
see https://forejune.co/cuda/ai/unsupervised/unsupercu.html
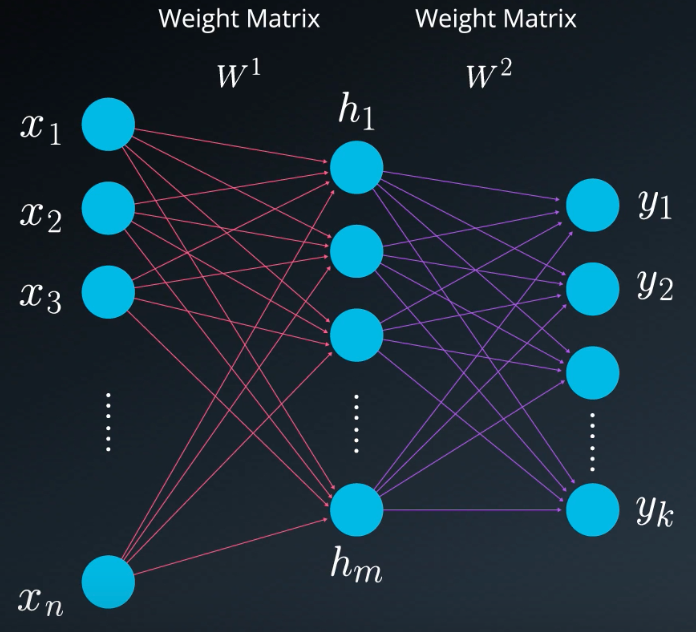
Multi-layer Perceptron (MLP)
see https://forejune.co/cuda/ai/mlp/mlpcu.html
Materials available at: https://forejune.co/cuda/
Overview
Review
K-means Clustering
see https://forejune.co/cuda/ai/unsupervised/unsupercu.html
Multi-layer Perceptron (MLP)
see https://forejune.co/cuda/ai/mlp/mlpcu.html
// mlpcu.h
// https://forejune.co/cuda
#ifndef __MLPCU_H__
#define __MLPCU_H__
using namespace std;
#define n1 3
#define m1 7
#define K 4
#define numSamples 600
#define eta 0.5
// Simple MLP class
class MLP
{
private:
double a[m1]; //linear sum of products of inputs and weights
double h[m1]; //hidden nodes h[j] = g(a[j])
double y[K]; //predicted output
double z[K]; //linear sum of products of weights and hidden nodes
double *d_inputs;
double *d_labels;
double *d_a;
double *d_h; //hidden layer
double *d_y; //output
double *d_yd; //desired output
double *d_z;
double *d_w;
double *d_wo;
public:
MLP();
//Sigmoid activation function
double g(double x);
//Derivative of sigmoid function
double gd(double x);
//Forward propagation
double* predicted(double x[]);
void train(const vector< Point> &points, int epochs);
~MLP();
};
#endif
|
// mlp.cu
// https://forejune.co/cuda
#include <iostream>
#include <iomanip>
#include <cmath>
#include <stdio.h>
#include "kmeanscu.h"
#include "mlpcu.h"
using namespace std;
double w[n1][m1];
double wo[m1][K];
//Sigmoid activation function
__device__ double d_g(double x)
{
return 1.0 / (1.0 + exp(-x));
}
//Derivative of sigmoid function
__device__ double d_gd(double x)
{
double s = d_g(x);
return s * (1 - s);
}
//y[] is the output
__global__ void d_forward(int k, double *w, double *wo, double *h, double *a,
double *z, double *y, double *d_inputs)
{
__shared__ double x[n1];
int ii = threadIdx.x; //indexing input nodes
int jj, ll;
if (ii < n1) //inputs
x[ii] = d_inputs[k*n1+ii];
__syncthreads();
//hidden layer activation, all hidden layer threads work in parallel
if ( ii >= n1 && ii < n1+m1) {
jj = ii - n1;
a[jj] = 0;
for (int i = 0; i < n1; i++)
a[jj] += w[i*m1+jj] * x[i];
if ( jj > 0 )
h[jj] = d_g(a[jj]); //sigmoid activation function
}
__syncthreads();
//output layer activation, all output layer threads work in parallel
if (ii >= n1 + m1){
ll = ii - n1 - m1;
z[ll] = 0;
for(int j = 0; j < m1; j++)
z[ll] += wo[j*K+ll] * h[j];
y[ll] = d_g( z[ll] );
}
__syncthreads();
}
//Backward propagation, yd is the desired output
__global__ void d_backward(int k, double *w, double *wo, double *h, double *a,
double *z, double *y, double *d_inputs, double *d_labels)
{
__shared__ double delta[m1];
__shared__ double deltao[K];
__shared__ double w_share[n1][m1]; //just for easier readability, not necessarily needed
__shared__ double wo_share[m1][K];
__shared__ double x[n1]; //inputs
__shared__ double yd[K]; //desired outputs
int ii = threadIdx.x; //indexing input nodes
int jj = threadIdx.y; //indexing hidden nodes
int ll = threadIdx.z; //indexing output nodes
if (jj == 0 && ll == 0 )
x[ii] = d_inputs[k*n1+ii];
__syncthreads();
if ( ii == 0 && jj == 0 )
yd[ll] = d_labels[k*K+ll];
__syncthreads();
if (ll == 0 )
w_share[ii][jj] = w[ii*m1+jj];
__syncthreads();
if (ii == 0 )
wo_share[jj][ll] = wo[jj*K+ll];
__syncthreads();
//output threads work in parallel
if (ii == 0 && jj == 0 ) {
double e = yd[ll] - y[ll]; //output layer error
deltao[ll] = e * d_gd(z[ll]);
}
__syncthreads();
//Compute hidden layer error, hidden threads work in parallel
if (ii == 0 && ll == 0 ) {
delta[jj] = 0;
for(int l = 0; l < K; l++)
delta[jj] += deltao[l] * wo_share[jj][l] * d_gd(a[jj]);
}
//delta[jj] += deltao[l] * wo[jj*K+l] * d_gd(a[jj]);
__syncthreads();
//Update weights (hidden to output), hidden and output threads work in parallel
if (ii == 0 ) {
wo_share[jj][ll] += eta * deltao[ll] * h[jj];
}
__syncthreads();
//Update weights (input to hidden), input and hidden threads work in parallel
if ( ll==0 ) {
w_share[ii][jj] += eta * delta[jj] * x[ii];
}
syncthreads();
if ( ll == 0 )
w[ii*m1+jj] = w_share[ii][jj];
__syncthreads();
if ( ii == 0 )
wo[jj*K+ll] = wo_share[jj][ll];
__syncthreads();
}
MLP::MLP()
{
int wSize = n1 * m1 * sizeof(double);
int woSize = m1 * K * sizeof(double);
cudaMalloc((void**)&d_inputs, numSamples * n1 * sizeof(double));
cudaMalloc((void**)&d_labels, numSamples * K * sizeof(double));
cudaMalloc((void**)&d_a, m1 * sizeof(double));
cudaMalloc((void**)&d_h, m1 * sizeof(double));
cudaMalloc((void**)&d_z, K * sizeof(double));
cudaMalloc((void**)&d_y, K * sizeof(double));
cudaMalloc((void**)&d_yd, K * sizeof(double));
cudaMalloc((void**)&d_w, wSize);
cudaMalloc((void**)&d_wo, woSize);
//random weights
for (int i = 0; i < n1; i++)
for (int j = 0; j < m1; j++)
w[i][j] = rand() % 1000 / 1000.0;
for (int j = 0; j < m1; j++)
for (int l = 0; l < K; l++)
wo[j][l] = rand() % 1000 / 1000.0;
cudaMemcpy(d_w, w, wSize, cudaMemcpyHostToDevice);
cudaMemcpy(d_wo, wo, woSize, cudaMemcpyHostToDevice);
h[0] = 1; //for bias
cudaMemcpy(d_h, h, m1 * sizeof(double), cudaMemcpyHostToDevice);
}
//Sigmoid activation function
double MLP::g(double x)
{
return 1.0 / (1.0 + exp(-x));
}
//Derivative of sigmoid function
double MLP::gd(double x)
{
double s = g(x);
return s * (1 - s);
}
//Forward propagation
double* MLP::predicted(double x[])
{
//hidden layer activation
for (int j = 0; j < m1; j++) {
a[j] = 0;
for (int i = 0; i < n1; i++)
a[j] += w[i][j] * x[i];
if ( j > 0 )
h[j] = g( a[j] );
}
//output layer activation
for (int l = 0; l < K; l++){
z[l] = 0;
for(int j = 0; j < m1; j++)
z[l] += wo[j][l] * h[j];
y[l] = g( z[l] );
}
return y; //return output
}
// Train the perceptron
// eta = learning rate
// epochs = number of times of training
// numSamples = number of different input sets (x_data)
// yd is target output
void MLP::train(const vector< Point> &points, int epochs)
{
double inputs[numSamples][n1];
double labels[numSamples][K];
dim3 threads(n1, m1, K); //input, hidden, output layers threads
for (int i = 0; i < numSamples; i++) {
inputs[i][0] = 1; //bias
inputs[i][1] = points[i].x;
inputs[i][2] = points[i].y;
}
for (int i = 0; i < numSamples; i++) {
for (int k = 0; k < K; k++)
if (points[i].cluster == k)
labels[i][k] = 1;
else
labels[i][k] = 0;
}
cudaMemcpy(d_inputs, inputs, numSamples*n1*sizeof(double), cudaMemcpyHostToDevice);
cudaMemcpy(d_labels, labels, numSamples*K*sizeof(double), cudaMemcpyHostToDevice);
for (int epoch = 0; epoch < epochs; epoch++){
for (int i = 0; i < numSamples; i++) {
//for simplicity, use more threads than needed
d_forward<<<1,n1+m1+K>>>(i, d_w, d_wo, d_h, d_a, d_z, d_y, d_inputs);
cudaDeviceSynchronize();
//for simplicity, use more threads than needed
d_backward<<<1, threads>>>(i, d_w, d_wo, d_h, d_a, d_z, d_y, d_inputs, d_labels);
cudaDeviceSynchronize();
}
}
//save the weights
cudaMemcpy(&w[0][0], d_w, sizeof(w), cudaMemcpyDeviceToHost);
cudaMemcpy(&wo[0][0], d_wo, sizeof(wo), cudaMemcpyDeviceToHost);
}
MLP::~MLP()
{
cudaFree(d_inputs);
cudaFree(d_labels);
cudaFree(d_a);
cudaFree(d_h);
cudaFree(d_z);
cudaFree(d_y);
}
|
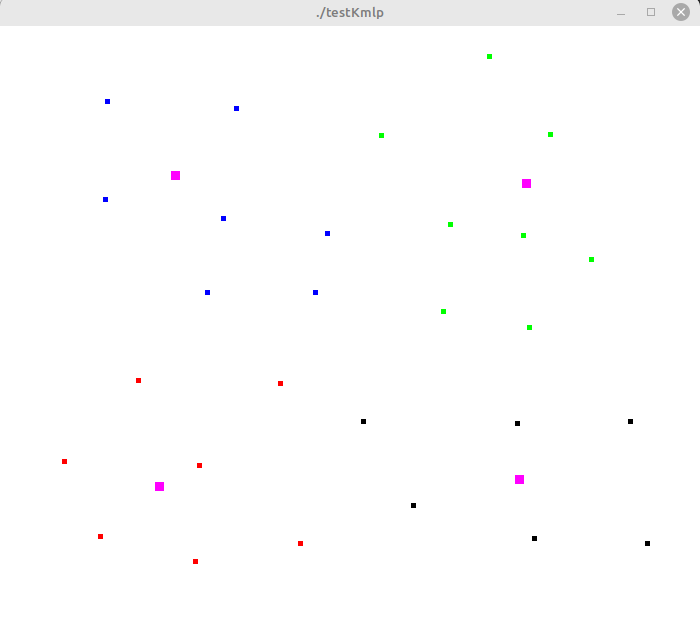
Testing K-means MLP routines
// testKmlp.cu
// https://forejune.co/cuda
#include <iostream>
#include <iomanip>
#include <cmath>
#include <stdio.h>
#include "kmeanscu.h"
#include "mlpcu.h"
using namespace std;
const int screenWidth = 800;
const int screenHeight = 700;
void graphics(int argc, char *argv[]);
int classifier( double y[])
{
int value = 0;
double max = y[0];
for (int i = 1; i < K; i++) {
if (y[i] > max) {
max = y[i];
value = i;
}
}
return value;
}
bool overlap(const vector<Centroid> & centroids)
{
int n = centroids.size();
for (int i = 0; i < n; i++)
for (int j=i+1; j < n; j++)
if ( abs(centroids[i].x - centroids[j].x) < 0.01 &&
abs(centroids[i].y - centroids[j].y) < 0.01 )
return true;
return false;
}
// cluster the points using MLP
void useMlp(MLP &mlp, vector<Point> &points, int delta)
{
int n = points.size();
double x[3];
x[0] = 1; //bias
int j = 0;
for (int i = 0; i < n; i+=delta) {
x[1] = points[i].x;
x[2] = points[i].y;
double *output = mlp.predicted(x);
cout << fixed << setprecision(2) << " " << x[1] << " " << x[2] << " : " <<
classifier(output) << "" << " (" << setprecision(1);
for(int k = 0; k < K; k++) {
cout << output[k];
if (k < K - 1)
cout << " ";
else
cout << ")" << "\t";
}
points[i].cluster = (int) classifier(output);
if (++j % 2 == 0) cout << endl;
}
}
MLP mlp;
vector<Centroid> centroids(K);
int main(int argc, char *argv[])
{
srand(time(0));
int iterations = 50; // Number of K-means iterations
// Generate data
vector<Point> points;
for (int i = 0; i < numSamples; ++i) {
Point p;
p.x = (float) (rand() % screenWidth) /screenWidth;
p.y = (float) (rand() % screenHeight) / screenHeight;
points.push_back(p);
}
int c[K];
// Randomly initialize centroids from points
do {
for (int i = 0; i < K; i++) {
c[i] = rand() % points.size();
centroids[i].x = points[c[i]].x;
centroids[i].y = points[c[i]].y;
}
} while (overlap(centroids));
kmeans(points, centroids, iterations);
int delta = 20;
//output results
int k = 0;
for (int j = 0; j < points.size(); j+=delta ) {
cout << fixed << setprecision(2) << "(" << points[j].x << ", " << points[j].y
<< ") : " << points[j].cluster << "\t";
if ( ++k % 2 == 0 ) cout << endl;
}
cout << endl;
cout << "Training the MLP ..." << endl;
mlp.train(points, 10000);
// Test the MLP
cout << "Testing MLP:" << endl;
useMlp(mlp, points, delta);
getchar();
graphics(argc, argv);
return 0;
}
// graphics routines
#include <GL/glut.h>
//vectors to store points
vector<Point>pointVec;
void init()
{
glClearColor(1, 1, 1, 1); //clear color buffer with white color
glClear(GL_COLOR_BUFFER_BIT); //clear color buffer
//define coordinate system
glMatrixMode(GL_PROJECTION);
glLoadIdentity();
gluOrtho2D(0, screenWidth, 0, screenHeight);
glPointSize( 3 );
glColor3f(0.0, 0.0, 0.0); //draw with black color
}
void display()
{
//flush out data to color buffer
glFlush();
}
//draw one point
void drawDot(int x, int y)
{
glBegin(GL_POINTS);
glVertex2i(x, y);
glEnd();
glFlush();
}
//display cluster points with different colors and centroids
void displayClusters( vector<Point> &points)
{
glClear(GL_COLOR_BUFFER_BIT); //clear color buffer
//display data points
int n = points.size();
int k = centroids.size();
glPointSize( 5 );
for (int i = 0; i < n; i++) {
int c = points[i].cluster;
float color[3] = {0}; //display color (R, G, B)
if ( c < 3 )
color[c] = 1; //Red, green or blue
//fourth color is black
glColor3fv(color);
drawDot(screenWidth*points[i].x, screenHeight*points[i].y);
}
//display centroids
glPointSize( 9 );
glColor3f(1, 0, 1); //magenta
for(int j = 0; j < k; j++)
drawDot(screenWidth*centroids[j].x, screenHeight*centroids[j].y);
glColor3f(0, 0, 0); //restore black color
glPointSize( 3 );
glutPostRedisplay();
}
void keyboard(unsigned char key, int x, int y)
{
switch ( key ) {
case 27: //escape
exit( -1 );
case 'd':
displayClusters(pointVec);
break;
case 'm':
useMlp(mlp, pointVec, 1);
break;
}
}
void mouse(int button, int state, int mx, int my)
{
int x = mx, y = screenHeight - my;
if ( button == GLUT_LEFT_BUTTON && state == GLUT_DOWN ){
drawDot(x, y);
Point pt = {(double) x / screenWidth, (double) y / screenHeight};
pointVec.push_back( pt );
}
glFlush();
}
void graphics(int argc, char *argv[])
{
glutInit(&argc, argv); //Initialization
glutInitDisplayMode(GLUT_SINGLE | GLUT_RGB );
glutInitWindowSize(screenWidth, screenHeight);
glutInitWindowPosition(59, 50);
glutCreateWindow( argv[0] );
init();
// specifies calback functions
glutKeyboardFunc( keyboard );
glutMouseFunc( mouse );
glutDisplayFunc( display );
glutMainLoop(); //go into perpetual loop
}
|
Using a Makefile:
CC=nvcc
testKmlp: testKmlp.o mlp.o kmeans.o
$(CC) -o testKmlp testKmlp.o mlp.o kmeans.o -lGL -lGLU -lglut
mlp.o:
$(CC) -c mlp.cu
kmeans.o:
$(CC) -c kmeans.cu
testKmlp.o:
$(CC) -c testKmlp.cu
clean:
rm mlp.o testKmlp.o
Sample Outputs:
(0.28, 0.27) : 3 (0.51, 0.80) : 0 (0.50, 0.11) : 1 (0.20, 0.36) : 3 (0.62, 0.67) : 0 (0.63, 0.69) : 0 (0.03, 0.45) : 3 (0.53, 0.01) : 1 (0.42, 0.69) : 2 (0.43, 0.91) : 2 (0.70, 0.18) : 1 (0.54, 0.62) : 0 (0.29, 0.47) : 3 (0.05, 0.80) : 2 (0.11, 0.20) : 3 (0.49, 0.55) : 0 (0.21, 0.89) : 2 (0.82, 0.39) : 1 (0.92, 0.73) : 0 (0.06, 0.55) : 2 (0.61, 0.33) : 1 (0.93, 0.25) : 1 (0.23, 0.88) : 2 (0.82, 0.83) : 0 (0.68, 0.18) : 1 (0.50, 0.04) : 1 (0.46, 0.25) : 3 (0.18, 0.95) : 2 (0.67, 0.34) : 1 (0.01, 0.41) : 3 Training the MLP ... Testing MLP: 0.28 0.27 : 3 (0.0 0.0 0.0 1.0) 0.51 0.80 : 0 (0.9 0.0 0.0 0.0) 0.50 0.11 : 1 (0.0 0.8 0.0 0.2) 0.20 0.36 : 3 (0.0 0.0 0.0 1.0) 0.62 0.67 : 0 (1.0 0.0 0.0 0.0) 0.63 0.69 : 0 (1.0 0.0 0.0 0.0) 0.03 0.45 : 3 (0.0 0.0 0.0 1.0) 0.53 0.01 : 1 (0.0 1.0 0.0 0.0) 0.42 0.69 : 2 (0.0 0.0 1.0 0.0) 0.43 0.91 : 2 (0.0 0.0 1.0 0.0) 0.70 0.18 : 1 (0.0 1.0 0.0 0.0) 0.54 0.62 : 0 (1.0 0.0 0.0 0.0) 0.29 0.47 : 3 (0.0 0.0 0.0 1.0) 0.05 0.80 : 2 (0.0 0.0 1.0 0.0) 0.11 0.20 : 3 (0.0 0.0 0.0 1.0) 0.49 0.55 : 0 (0.3 0.0 0.0 0.0) 0.21 0.89 : 2 (0.0 0.0 1.0 0.0) 0.82 0.39 : 1 (0.0 1.0 0.0 0.0) 0.92 0.73 : 0 (1.0 0.0 0.0 0.0) 0.06 0.55 : 2 (0.0 0.0 1.0 0.0) 0.61 0.33 : 1 (0.0 1.0 0.0 0.0) 0.93 0.25 : 1 (0.0 1.0 0.0 0.0) 0.23 0.88 : 2 (0.0 0.0 1.0 0.0) 0.82 0.83 : 0 (1.0 0.0 0.0 0.0) 0.68 0.18 : 1 (0.0 1.0 0.0 0.0) 0.50 0.04 : 1 (0.0 0.9 0.0 0.0) 0.46 0.25 : 3 (0.0 0.0 0.0 1.0) 0.18 0.95 : 2 (0.0 0.0 1.0 0.0) 0.67 0.34 : 1 (0.0 1.0 0.0 0.0) 0.01 0.41 : 3 (0.0 0.0 0.0 1.0)