A ``Hello World" Example of Supervised Learning in
Artificial Intelligence Using Multilayer Perceptron and
Backpropagation in CUDA
Materials available at: https://forejune.co/cuda/
Reviews
Perceptron
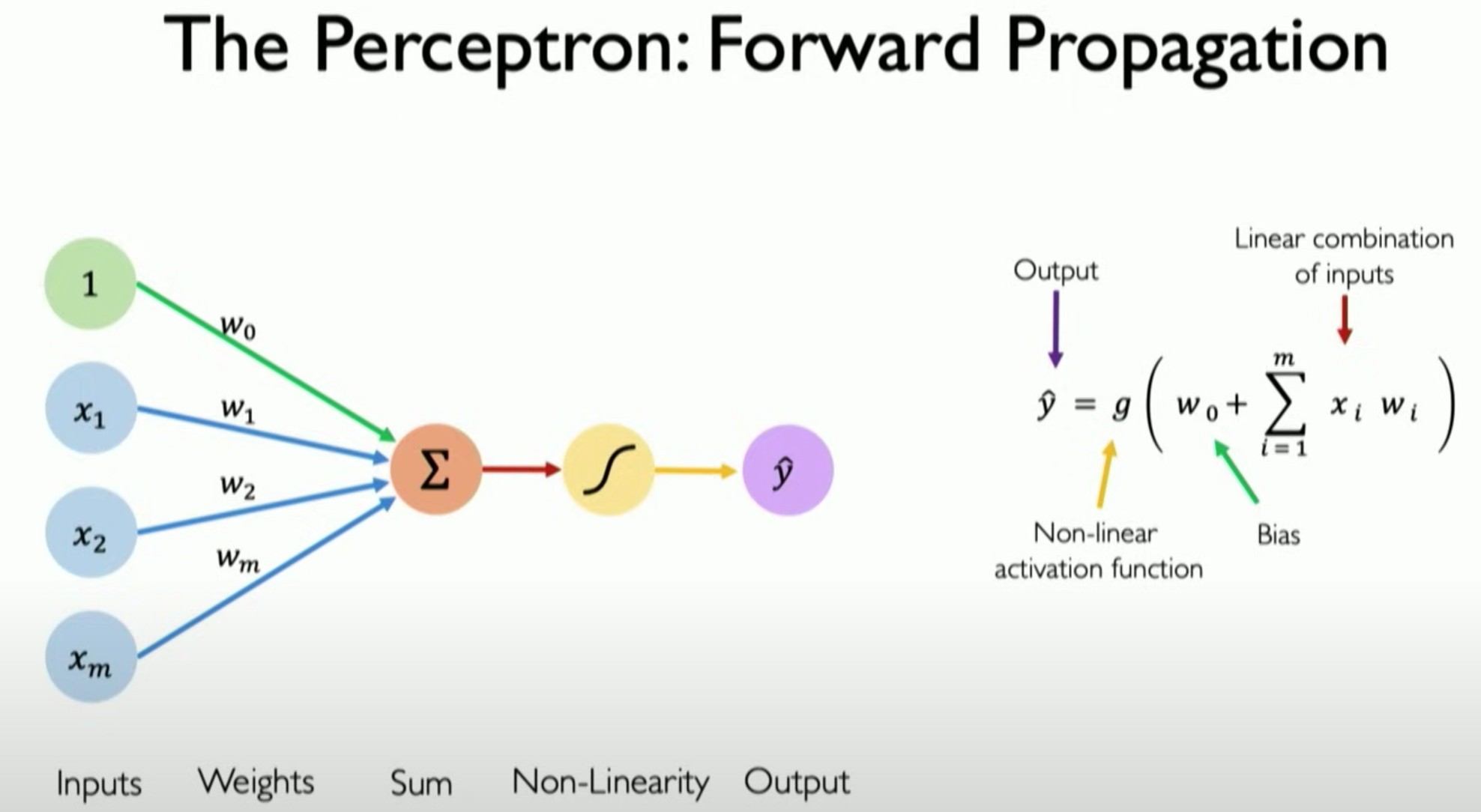
Activation function:
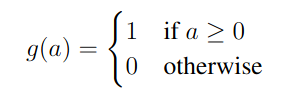
Learning in a perceptron: Initialization: Start with random weights and bias. Prediction: For each input, compute the output using the current weights and bias. with x0 = 1 Update: Update the weights and bias.
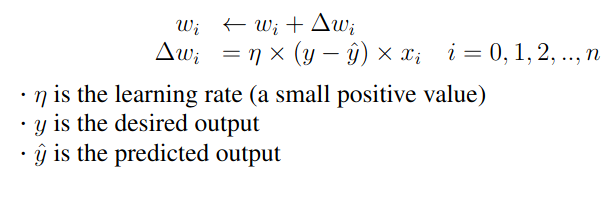
Can only learn linearly separable patterns.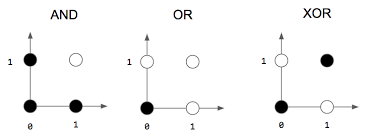
Able to distinguish data that are not linearly separable
General IdeaError Function: Mean Squared Error (MSE)
1. Feed the MLP an input pattern x = (x1, x2, ...., xn) from the training set. 2. MLP generates an output pattern y = (y1, y2, ...., yk) 3. Compare y with the desired output or target yd, to get the error quantity. 4. Adjust the weights using the error quantity so that in the next iteration,y will be closer to yd. 5. Repeat with another input pattern x from the training set.After performing a series of straightforward mathematical derivations, one can arrive at the following algorithm that trains an MLP.
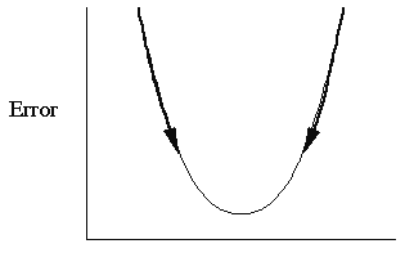
Adjust the weights so that E decreases. A common technique used: Gradient descent Adjust the weights so that E decreases along the gradient.

1. Notations
Inputs: x1, x2, ..., xn
Hidden Nodes: h1, h2, ..., hm
Outputs: y1, y2, ..., yk
Weights: wij (weight from node i to node j)
Activation Function: Sigmoid function
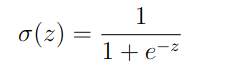
Derivative of Sigmoid function:
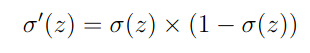
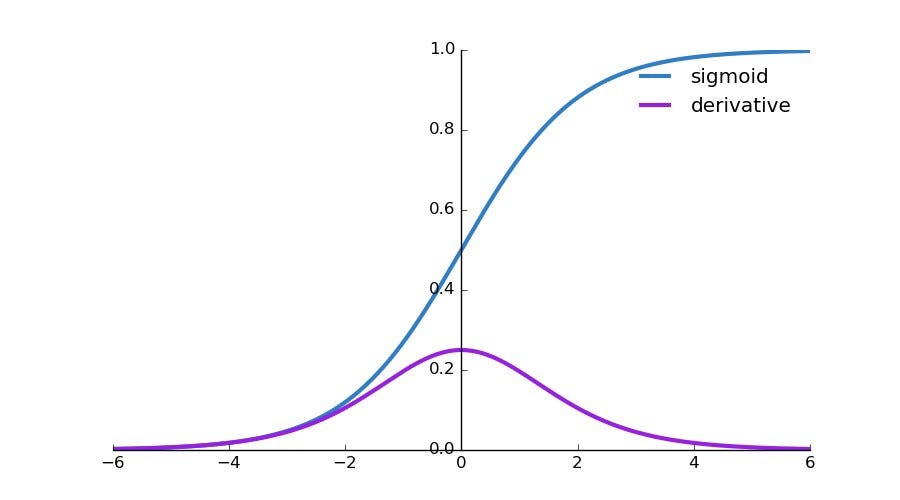
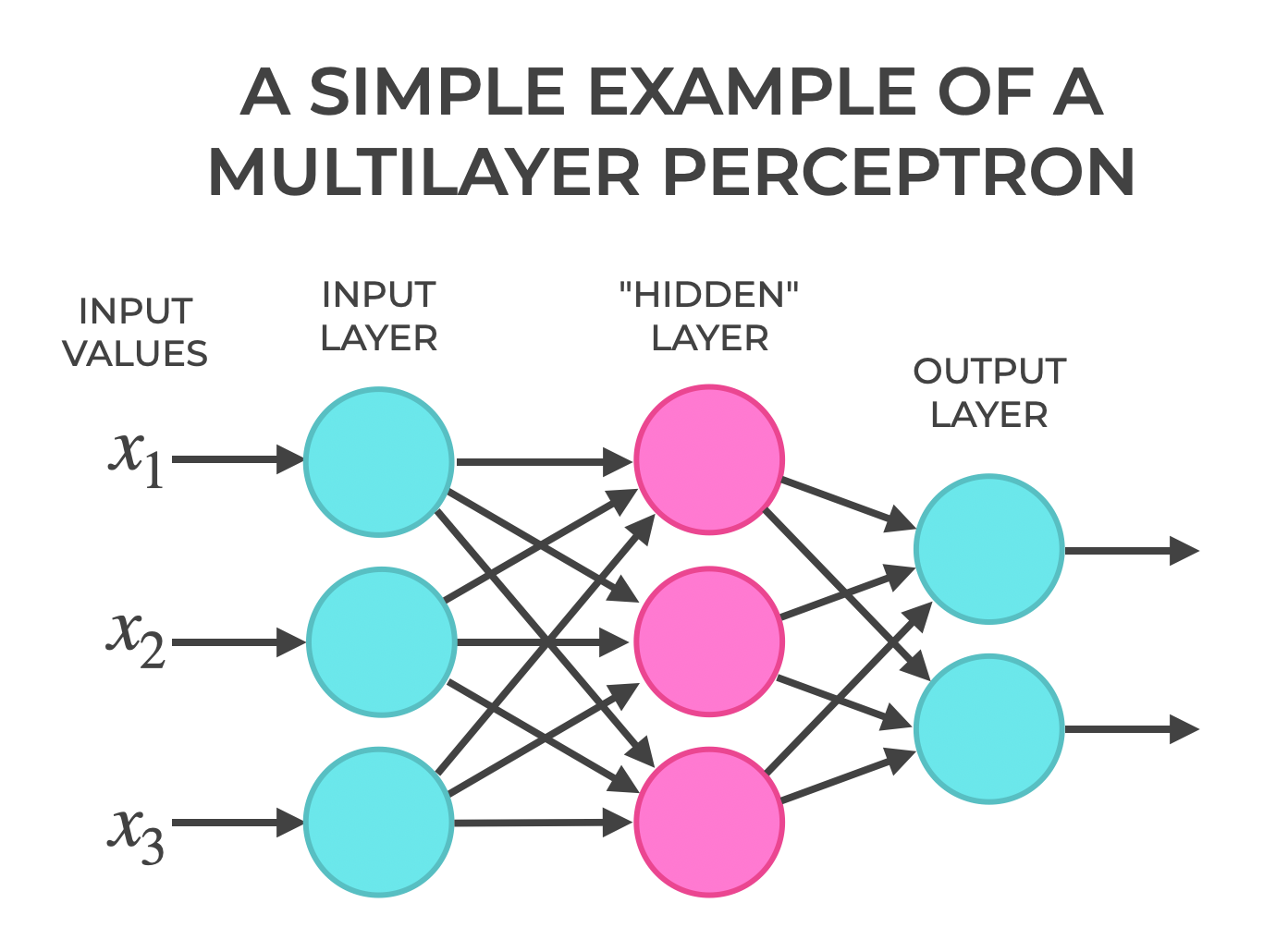
2. Structure of MLP
The MLP consists of three layers:
Input Layer, Hidden Layer, Output Layer
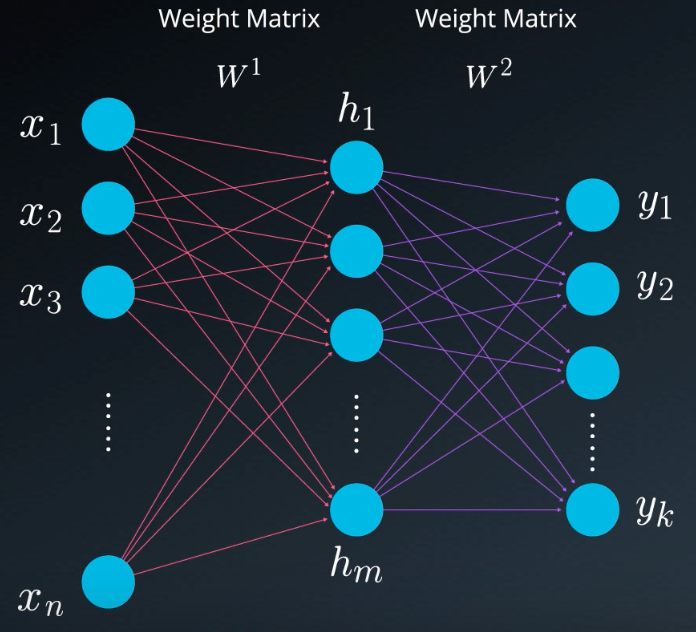
Weights:
wij: Weight from input xi to hidden node hj.
wojl: Weight from hidden node hj to output node yl
3. Forward Propagation
Computes the output of the network from inputs:
Step 1: Compute Hidden Layer Activations
Each nuron hj computes
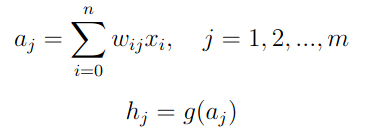 g is the activation function σ
w0j is the bias, and x0 = 1
Step 2: Compute Output Layer Activations
Each output node yl computes the weighted sum of hidden layer
activations and apply the activation function:
g is the activation function σ
w0j is the bias, and x0 = 1
Step 2: Compute Output Layer Activations
Each output node yl computes the weighted sum of hidden layer
activations and apply the activation function:
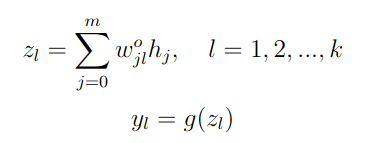 wo0l is the bias, and h0 = 1
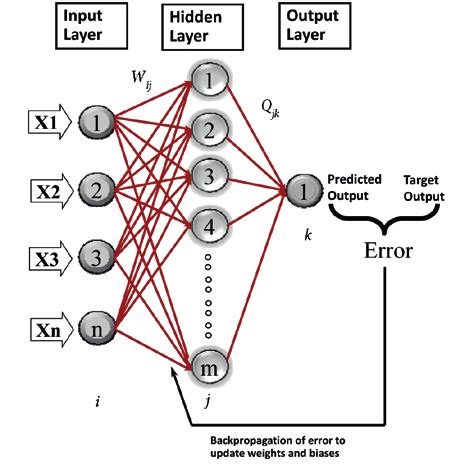
4. Backward Propagation
wo0l is the bias, and h0 = 1
4. Backward Propagation

XOR
x1 x2 | x1 XOR x2
------|-----------
0 0 | 0
0 1 | 1
1 0 | 1
1 1 | 0
//mlp.cpp
#include <iostream>
#include <iomanip>
#include <cmath>
using namespace std;
//MLP training for an XOR gate
const int n1 = 3; //number of inputs and bias
const int m1 = 3; //number of hidden nodes and bias
const int K = 1; //number of outputs
const int numSamples = 4;
double inputs[numSamples][n1] =
{
1, 0, 0, //x0=1, x1=0, x2=0
1, 0, 1, //x0=1, x1=0, x2=1
1, 1, 0, //x0=1, x1=1, x2=0
1, 1, 1 //x0=1, x1=1, x2=1
};
double labels[numSamples][K] = {0, 1, 1, 0};//target outputs (labels)
double w[n1][m1] = {0.97, 0.2, 0.7,//random weights (input to hidden)
0.73, 0.1, 0.9,
0.2, 0.7, 0.3};
double wo[m1][K] = {0.76, 0.6, 0.1};//random weights (hidden to output)
// Simple MLP class
class MLP
{
private:
double a[m1]; //linear sum of products of inputs and weights
double h[m1]; //hidden nodes h[j] = g(a[j])
double y[K]; //predicted output
double z[K]; //linear sum of products of weights and hidden nodes
double eta; //learning rate
public:
MLP(double learning_rate)
{
eta = learning_rate;
h[0] = 1; //for bias
}
//Sigmoid activation function
double g(double x)
{
return 1.0 / (1.0 + exp(-x));
}
//Derivative of sigmoid function
double gd(double x)
{
double s = g(x);
return s * (1 - s);
}
//Forward propagation
double* forward(double x[])
{
//hidden layer activation
for (int j = 0; j < m1; j++) {
a[j] = 0;
for (int i = 0; i < n1; i++)
a[j] += w[i][j] * x[i];
if ( j > 0 )
h[j] = g( a[j] );
}
//output layer activation
for (int l = 0; l < K; l++){
z[l] = 0;
for(int j = 0; j < m1; j++)
z[l] += wo[j][l] * h[j];
y[l] = g( z[l] );
}
return y; //return output
}
//Backward propagation, yd is the desired output
void backward(double yd[], double x[])
{
double delta[m1];
double deltao[K];
for (int l = 0; l < K; l++) {
double e = yd[l] - y[l]; //output layer error
deltao[l] = e * gd(z[l]);
}
//Compute hidden layer error
for(int j = 0; j < m1; j++){
delta[j] = 0;
for(int l = 0; l < K; l++)
delta[j] += deltao[l] * wo[j][l] * gd(a[j]);
}
//Update weights (hidden to output)
for(int j = 0; j < m1; j++)
for(int l = 0; l < K; l++)
wo[j][l] += eta * deltao[l] * h[j];
//Update weights (input to hidden)
for(int i = 0; i < n1; i++)
for(int j = 0; j < m1; j++)
w[i][j] += eta * delta[j] * x[i];
}
void get_input_data(int k, double x[])
{
for(int i=0; i < n1; i++)
x[i]=inputs[k][i];
}
// Train the MLP
// epochs = number of times of training
// numSamples = number of different input sets
void train(int numSamples, int epochs)
{
double x[n1]; //inputs
double *yd = &labels[0][0];
for (int epoch = 0; epoch < epochs; epoch++){
for (int k = 0; k < numSamples; k++) {
get_input_data(k, x);
forward( x );
backward(yd+k*K, x);
}
}
}
void printWeights()
{
cout << "\nMLP input to hidden weights: ";
for(int i = 0; i < n1; i++){
cout << endl;
for(int j = 0; j < m1; j++)
printf("w[%d][%d]: %5.3f\t", i, j, w[i][j]);
}
cout << "\nMLP hidden to output weights:";
for(int i = 0; i < m1; i++) {
cout << endl;
for(int j = 0; j < K; j++)
printf("wo[%d][%d]: %5.3f\t", i, j, wo[i][j]);
}
}
~MLP()
{
}
};
int classifier( double x)
{
if ( x < 0.2 && x > -0.1)
return 0;
if ( x > 0.8 && x < 1.1)
return 1;
return -1;
}
int main()
{
string gates = " XOR ";
MLP mlp(0.5);
mlp.train(4, 10000);
// Test the MLP
double x[3];
cout << "\nTesting MLP:" << endl;
x[0] = 1;
for (int i = 0; i < 4; i++) {
x[1] = i & 1;
x[2] = i >> 1;
double *output = mlp.forward(x);
cout << fixed << setprecision(0) << " " << x[2]
<< gates << x[1] << " = " << classifier(*output) <<
setprecision(2) << " (" << output[0]<<")" << endl;
}
mlp.printWeights();
cout << endl << "Hello, AI World!" << endl;
return 0;
}
|
CUDA Implementation
3 groups of threads
1 group -- input nodes n1
1 group -- hidden nodes m1
1 group -- output nodes K
dim3 threads(n1, m1, K);
Thread indexes:
threadIdx.x -- indexing input nodes
threadIdx.y -- indexing hidden nodes
threadIdx.z -- indexing output nodes
//xorMLP.cu
#include <iostream>
#include <iomanip>
#include <cmath>
#include <stdio.h>
using namespace std;
#define n1 3
#define m1 3
#define K 1
#define numSamples 4
#define eta 0.5
double w[n1][m1] = {0.99, 0.2, 0.7, //random weights (input to hidden)
0.73, 0.1, 0.9,
0.2, 0.7, 0.3};
double wo[m1][K] = {0.88, 0.6, 0.1}; //random weights (hidden to output)
__device__ const double d_inputs[numSamples][n1] =
{
1, 0, 0, //x0=1, x1=0, x2=1
1, 0, 1, //x0=1, x1=0, x2=1
1, 1, 0, //x0=1, x1=1, x2=0
1, 1, 1 //x0=1, x1=1, x2=1
};
__device__ const double d_labels[numSamples][K] = {0, 1, 1, 0};//target outputs (labels)
//Sigmoid activation function
__device__ double d_g(double x)
{
return 1.0 / (1.0 + exp(-x));
}
//Derivative of sigmoid function
__device__ double d_gd(double x)
{
double s = d_g(x);
return s * (1 - s);
}
//y[] is the output
__global__ void d_forward(int k, double *w, double *wo, double *h, double *a, double *z, double *y)
{
__shared__ double x[n1];
int ii = threadIdx.x; //indexing input nodes
int jj = threadIdx.y; //indexing hidden nodes
int ll = threadIdx.z; //indexing output nodes
x[ii]= d_inputs[k][ii]; //get input data, input threads work in parallel
__syncthreads();
//hidden layer activation, all hidden layer threads work in parallel
a[jj] = 0;
for (int i = 0; i < n1; i++)
a[jj] += w[i*m1+jj] * x[i];
if ( jj > 0 )
h[jj] = d_g(a[jj]); //sigmoid activation function
__syncthreads();
//output layer activation, all output layer threads work in parallel
z[ll] = 0;
for(int j = 0; j < m1; j++)
z[ll] += wo[j*K+ll] * h[j];
y[ll] = d_g( z[ll] );
}
//Backward propagation, yd is the desired output
__global__ void d_backward(int k, double *w, double *wo, double *h, double *a, double *z, double *y)
{
double delta[m1];
double deltao[K];
__shared__ double x[n1]; //inputs
__shared__ double yd[K]; //desired outputs
int ii = threadIdx.x; //indexing input nodes
int jj = threadIdx.y; //indexing hidden nodes
int ll = threadIdx.z; //indexing output nodes
x[ii] = d_inputs[k][ii]; //get inputs, input threads work in parallel
yd[ll]= d_labels[k][ll]; //get target ouputs, output threads work in parallel
__syncthreads();
//output threads work in parallel
double e = yd[ll] - y[ll]; //output layer error
deltao[ll] = e * d_gd(z[ll]);
__syncthreads();
//Compute hidden layer error, hidden threads work in parallel
delta[jj] = 0;
for(int l = 0; l < K; l++)
delta[jj] += deltao[l] * wo[jj*K+l] * d_gd(a[jj]);
__syncthreads();
//Update weights (hidden to output), hidden and output threads work in parallel
wo[jj*K+ll] += eta * deltao[ll] * h[jj];
__syncthreads();
//Update weights (input to hidden), input and hidden threads work in parallel
w[ii*m1+jj] += eta * delta[jj] * x[ii];
__syncthreads();
}
// Simple MLP class
class MLP
{
private:
double a[m1]; //linear sum of products of inputs and weights
double h[m1]; //hidden nodes h[j] = g(a[j])
double y[K]; //predicted output
double z[K]; //linear sum of products of weights and hidden nodes
double *d_a;
double *d_h; //hidden layer
double *d_y; //output
double *d_yd; //desired output
double *d_z;
double *d_w;
double *d_wo;
public:
MLP()
{
int wSize = n1 * m1 * sizeof(double);
int woSize = m1 * K * sizeof(double);
cudaMalloc((void**)&d_a, m1 * sizeof(double));
cudaMalloc((void**)&d_h, m1 * sizeof(double));
cudaMalloc((void**)&d_z, K * sizeof(double));
cudaMalloc((void**)&d_y, K * sizeof(double));
cudaMalloc((void**)&d_yd, K * sizeof(double));
cudaMalloc((void**)&d_w, wSize);
cudaMalloc((void**)&d_wo, woSize);
cudaMemcpy(d_w, w, wSize, cudaMemcpyHostToDevice);
cudaMemcpy(d_wo, wo, woSize, cudaMemcpyHostToDevice);
h[0] = 1; //for bias
cudaMemcpy(d_h, h, m1 * sizeof(double), cudaMemcpyHostToDevice);
}
//Sigmoid activation function
double g(double x)
{
return 1.0 / (1.0 + exp(-x));
}
//Derivative of sigmoid function
double gd(double x)
{
double s = g(x);
return s * (1 - s);
}
//Forward propagation
double* predicted(double x[])
{
//hidden layer activation
for (int j = 0; j < m1; j++) {
a[j] = 0;
for (int i = 0; i < n1; i++)
a[j] += w[i][j] * x[i];
if ( j > 0 )
h[j] = g( a[j] );
}
//output layer activation
for (int l = 0; l < K; l++){
z[l] = 0;
for(int j = 0; j < m1; j++)
z[l] += wo[j][l] * h[j];
y[l] = g( z[l] );
}
return y; //return output
}
// Train the perceptron
// eta = learning rate
// epochs = number of times of training
// numSamples = number of different input sets (x_data)
// yd is target output
void train(int epochs)
{
dim3 threads(n1, m1, K); //input, hidden, output layers threads
for (int epoch = 0; epoch < epochs; epoch++){
for (int k = 0; k < numSamples; k++) {
d_forward<<<1,threads>>>(k, d_w, d_wo, d_h, d_a, d_z, d_y);
cudaDeviceSynchronize();
d_backward<<<1, threads>>>(k, d_w, d_wo, d_h, d_a, d_z, d_y);
cudaDeviceSynchronize();
}
}
//save the weights
cudaMemcpy(&w[0][0], d_w, sizeof(w), cudaMemcpyDeviceToHost);
cudaMemcpy(&wo[0][0], d_wo, sizeof(wo), cudaMemcpyDeviceToHost);
}
void printWeights()
{
cout << "\nMLP input to hidden weights: ";
for(int i = 0; i < n1; i++){
cout << endl;
for(int j = 0; j < m1; j++)
printf("w[%d][%d]: %5.3f\t", i, j, w[i][j]);
// cout << " w[i" << i*n1+j <<": " << w[i*m1+j];
}
cout << "\nMLP hidden to output weights:";
for(int i = 0; i < m1; i++) {
cout << endl;
for(int j = 0; j < K; j++)
printf("wo[%d][%d]: %5.3f\t", i, j, wo[i][j]);
//cout << " wo" << i <<": " << wo[i*K+j];
}
}
~MLP()
{
cudaFree(d_a);
cudaFree(d_h);
cudaFree(d_z);
cudaFree(d_y);
}
};
int classifier( double x)
{
if ( x < 0.2 && x > -0.1)
return 0;
if ( x > 0.8 && x < 1.1)
return 1;
return -1;
}
int main()
{
string gates = " XOR ";
MLP mlp;
mlp.train(10000);
// Test the MLP
double x[3];
cout << "Testing MLP:" << endl;
x[0] = 1;
for (int i = 0; i < 4; i++) {
x[1] = i & 1;
x[2] = i >> 1;
double *output = mlp.predicted(x);
cout << fixed << setprecision(0) << " " << x[2] << gates << x[1] << " = "
<< classifier(*output) << setprecision(2) << " (" << output[0]<<")" << endl;
}
mlp.printWeights();
cout << endl << "Hello, AI World!" << endl;
return 0;
}
Binary Full Adder
x1
x2
+ x3
-----------------
C S
x3 x2 x1 | C S
---------|-----------
0 0 0 | 0 0
0 0 1 | 0 1
0 1 0 | 0 1
0 1 1 | 1 0
1 0 0 | 0 1
1 0 1 | 1 0
1 1 0 | 1 0
1 1 1 | 1 1
3 inputs, 2 outputs, i.e. n1 = 4, K = 2
use 4 hidden nodes, so m1 = 5