Tokenization, Embedding, Positional Encoding,
Multi-head Attention and Sublayers of an AI
Transformer in C/C++ (Part 2)
Materials available at: http://forejune.co/cuda/
Recap
Helper Functions
#ifndef __UTIL_H__ #define __UTIL_H__ #include <vector> #include <algorithm> #include <math.h> #include <iostream> #include <iomanip> #include <random> using namespace std; typedef vector<vector<double>> matrixd; // an activation function double f(double z); // softmax, 1D input vector<double> softmax(const vector<double> &v); // softmax activation function, 2D input vector matrixd softmax(const matrixd& input); // add two matrices matrixd addMat(const matrixd &A, const matrixd &B); // Transpose matrix n x m, B = A^T : m x n matrixd transpose(const matrixd& A); // Matrix multiplication C = A X B A: nxm, B: mxr, C: nxr matrixd matmul(const matrixd& A, const matrixd& B); // initialize an input matrix with certain random values void initMatrix(matrixd& M, const int n, const int m); // print a token dictionary void printDictionary(unordered_map<string, int> &d); // print a matrix void printMatrix(const matrixd &y); #endif |
util.cpp:
#include "util.h"
using namespace std;
typedef vector<vector<double>> matrixd;
// Activation function: using ReLU (Rectified Linear Unit)
double f(double z)
{
return max(0.0, z);
}
// softmax activation function, 1D input vector
vector<double> softmax(const vector<double> &z)
{
int m = z.size();
vector<double> y(m, 0);
//maximum value of vector
double maxVal = *max_element(z.begin(), z.end());
double sum = 0;
// Subtract max for numerical stability
for (int j = 0; j < m; j++) {
y[j] = exp(z[j] - maxVal);
sum += y[j];
}
// Normalize
for (int j = 0; j < m; j++)
y[j] /= sum;
return y;
}
// softmax activation function, 2D input vector
matrixd softmax(const matrixd& input)
{
int n = input.size(), m = input[0].size(); // n x m matrix
// 2D output vector n x m y[n][m]
vector<vector<double>> y(n, vector<double>(m));
for (int i = 0; i < n; i++) {
//maximum value of the row
double maxVal = *max_element(input[i].begin(), input[i].end());
double sum = 0;
// Subtract max for numerical stability
for (int j = 0; j < m; j++) {
y[i][j] = exp(input[i][j] - maxVal);
sum += y[i][j];
}
// Normalize
for (int j = 0; j < input[i].size(); j++)
y[i][j] /= sum;
}
return y;
}
// C = A + B
matrixd addMat(const matrixd &A, const matrixd &B)
{
int n = A.size(); // rows
int m = A[0].size(); // cols
matrixd C = A; // same size as A
for (int i = 0; i < n; i++)
for(int j = 0; j < m; j++)
C[i][j] = A[i][j] + B[i][j];
return C;
}
// Transpose matrix n x m, B = A^T : m x n
//vector<vector<double>> transpose(const vector<vector<double>>& A)
matrixd transpose(const matrixd& A)
{
int n = A.size(); //number of rows
int m = A[0].size(); //number of columns
matrixd B(m, vector<double>(n));
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
B[j][i] = A[i][j];
return B;
}
// Matrix multiplication C = A X B A: nxm, B: mxr, C: nxr
matrixd matmul(const matrixd& A, const matrixd& B)
{
int n = A.size();
int m = A[0].size();
int r = B[0].size();
matrixd C(n, vector<double>(r, 0));
for (int i = 0; i < n; i++)
for (int j = 0; j < r; j++)
for (int k = 0; k < m; k++)
C[i][j] += A[i][k] * B[k][j];
return C;
}
void initMatrix(matrixd& M, const int n, const int m)
{
// resizing 2D vector to n x m with initial values 0
M.assign(n, vector<double>(m, 0));
random_device rd;
mt19937 gen(rd()); //psuedo random number generator
//mean = 0.0, standard deviation (sigma = 0.2)
normal_distribution<double> dist(0.0, 0.2);
for (int i = 0; i < n; ++i)
for (int j = 0; j < m; ++j)
M[i][j] = dist(gen);
}
void printDictionary(unordered_map<string, int> &d)
{
unordered_map<string, int>::iterator it = d.begin();
int k = 0;
while ( it != d.end() ){
cout << right << setw(12) << it->first << ": " << setw(3) << it->second;
it++;
k++;
if ( k % 5 == 0 )
cout << endl;
}
}
void printMatrix(const matrixd &y)
{
int cols = y.size();
int rows = y[0].size();
for (int i = 0; i < cols; ++i) {
cout << "Token " << i << ": [";
for (int j = 0; j < rows; ++j) {
cout << fixed << setw(7) << setprecision(3) << y[i][j];
if (j < 4) cout << ", ";
}
cout << " ]\n";
}
}
|
#ifndef __TRANSFORMER_H__
#define __TRANSFORMER_H__
#include <fstream>
#include <vector>
#include <string>
#include <unordered_map>
using namespace std;
class Tokenizer
{
private:
unordered_map<string, int> words;
unordered_map<int, string> wordIndex;
int nTokens; // number of words
public:
Tokenizer();
Tokenizer(ifstream &fs);
unordered_map<string, int> getTokensWords();
vector<int> tokenize(const string& str);
string detokenize(const vector<int>& tokenIDs);
int get_nTokens() const;
};
class Embedding
{
private:
int nTokens; // number of words
int dim; // embedding dimension
matrixd em_matrix; // embedding matrix;
public:
Embedding(int sequence_length, int embeddingDimension);
// create embedding matrix with tokenIDs
matrixd embed(const vector<int>& tokenIDs);
int get_embedDim() const;
int get_nTokens() const;
};
class PositionalEncoding
{
private:
int maxTokens; // maximum sequence length
int dModel; // embedding dimension
matrixd PE; // positional_encodings matrix;
public:
PositionalEncoding(int max_seq, int embed_dimension);
matrixd addPE(const matrixd& embeddings);
matrixd getPE();
};
class MultiHeadAttention {
private:
int dModel;
int nHeads;
int d_k; // dimension per head
matrixd WQ, WK, WV, WO;
public:
MultiHeadAttention(int dm, int nh);
// input nTokens x dModel
matrixd computeAttention(const matrixd &X);
};
class TransformerEncoder {
private:
int dModel; // dimension of whole model
int nHeads; // number of heads
int d_k; // dimension of each head
int d_ff; // feed-forward network dimension
int nTokens;// number of tokens
MultiHeadAttention *mha;
public:
TransformerEncoder(int embedding_dim, int num_heads,
int ff_dim);
matrixd mhAttention(const matrixd &X);
matrixd addNnorm(const matrixd &A, const matrixd &B);
matrixd FeedForward(const matrixd& x, const matrixd& w1,
const matrixd& w2);
};
#endif
|
|
transformer.cpp:
// transformer.cpp -- classes of a multi-head transformer
// http://forejune.co/cuda/
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <unordered_map>
#include <cmath>
#include <random>
#include <algorithm>
#include <iomanip>
#include "util.h"
#include "transformer.h"
using namespace std;
// ------------------------ Tokenizer class --------------------------
Tokenizer::Tokenizer()
{
// Create a simple dictionary
words = {
{"[UNK]", 0}, {"[PAD]", 1}, {"[CLS]", 2}, {"[SEP]", 3},
{"strong", 4}, {"nation", 5}, {"recycles", 6}, {"its", 7},
{"huge", 8}, {"trade", 9}, {"surplus", 10}, {"to", 11},
{"america", 12}, {"to", 13}, {"infiltrate", 14}, {"it", 15}, {"!", 16}
};
// Create reverse mapping
nTokens = words.size();
nTokens = words.size();
unordered_map<string, int>::iterator it = words.begin();
while ( it != words.end() ) {
wordIndex[it->second] = it->first;
it++;
}
}
Tokenizer::Tokenizer(ifstream &fs)
{
string token;
vector<string> tokens;
// Read tokens (words) one by one, delimited by whitespace
int k = 0;
words["[UNK]"] = k; //unknown token
wordIndex[k] = "UNK]";
k++;
while (fs >> token) {
if (!words.contains(token)){
words[token] = k;
wordIndex[k] = token;
k++;
}
}
nTokens = words.size();
}
unordered_map<string, int> Tokenizer::getTokensWords()
{
return words;
}
// tokenize a string
vector<int> Tokenizer::tokenize(const string& str)
{
vector<int> tokenIDs;
string token;
// Simple tokenization
for (char c : str) {
if (isalnum(c)) {
//change character to lower case, add it to current token string
token += tolower(c);
} else { // non-alpha numeric, form a complete token
if (!token.empty()) { //string not empty
if (words.find(token) != words.end())
// token is in the words dictionary, thus save its ID
tokenIDs.push_back(words[token]);
else // unknown token
tokenIDs.push_back(words["[UNK]"]);
token.clear(); // clear variable to form next token
}
if (c == '!') // special token
tokenIDs.push_back(words["!"]);
}
}
// possible last token
if (!token.empty()) {
if (words.find(token) != words.end())
tokenIDs.push_back(words[token]);
else
tokenIDs.push_back(words["[UNK]"]);
}
return tokenIDs;
}
// Change a vector of tokens back to text
string Tokenizer::detokenize(const vector<int>& tokenIDs)
{
string str;
for (int i = 0; i < tokenIDs.size(); i++) {
if (wordIndex.find(tokenIDs[i]) != wordIndex.end()) {
str += wordIndex[tokenIDs[i]];
// add a delimiter
if (i < tokenIDs.size() - 1 && wordIndex[tokenIDs[i+1]] != "!")
str += " ";
}
}
return str;
}
int Tokenizer::get_nTokens() const
{
return nTokens;
}
//------------------ Embedding Class ------------------
Embedding::Embedding(int sequence_length, int embeddingDimension)
{
nTokens = sequence_length;
dim = embeddingDimension;
// initialize embeddings as an nTokens x dim matrix with certain random values
initMatrix(em_matrix, nTokens, dim);
}
// create embedding matrix with tokenIDs
matrixd Embedding::embed(const vector<int>& tokenIDs)
{
matrixd embeddings;
embeddings.reserve(tokenIDs.size()); // set capacity of embeddings vector
for(int i = 0; i < tokenIDs.size(); i++) {
if (tokenIDs[i] >= 0 && tokenIDs[i] < nTokens)
embeddings.push_back(em_matrix[tokenIDs[i]]);
else
// Out-of-dictionary tokens
embeddings.push_back(vector<double>(dim, 0.0));
}
return embeddings;
}
int Embedding::get_embedDim() const
{
return dim;
}
int Embedding::get_nTokens() const
{
return nTokens;
}
// --------------------- Positional Encoding class ---------------
PositionalEncoding::PositionalEncoding(int max_seq_length, int embed_dimension)
{
maxTokens = max_seq_length;
dModel = embed_dimension;
PE.resize(maxTokens, vector<double>(dModel));
for (int pos = 0; pos < maxTokens; pos++) {
for (int i = 0; i < dModel/2; i++) {
PE[pos][2*i] = sin( pos / pow(10000, 2.0*i/dModel) );
PE[pos][2*i+1] = cos( pos / pow(10000, 2.0*i/dModel) );
}
}
}
// add positional encodings to embeddings
matrixd PositionalEncoding::addPE(const matrixd& embeddings)
{
matrixd x = embeddings;
int nTokens = embeddings.size();
for (int pos = 0; pos < nTokens; pos++)
for (int i = 0; i < dModel; i++)
x[pos][i] += PE[pos][i];
return x;
}
matrixd PositionalEncoding::getPE()
{
return PE;
} |
// ------------------------- Multi-Head Attention Class ---------------
MultiHeadAttention::MultiHeadAttention(int dm, int nh)
{
dModel = dm; //embedding dimension
nHeads = nh; //number of heads
d_k = dModel / nHeads;
// initialize weight matrices with some random values
initMatrix(WQ, dModel, dModel);
initMatrix(WK, dModel, dModel);
initMatrix(WV, dModel, dModel);
initMatrix(WO, dModel, dModel);
}
// input Matrix X: nTokens x dModel
matrixd MultiHeadAttention::computeAttention(const matrixd &X)
{
// X contains the embeddings, WQ ... are weight matrices
auto Q = matmul(X, WQ);
auto K = matmul(X, WK);
auto V = matmul(X, WV);
int nTokens = X.size();
// cancat outputs of heads
matrixd head_outputs;
// each head: nTokens x d_k
head_outputs.assign(nHeads, vector<double>(dModel, 0));
for (int h = 0; h < nHeads; h++){
// for each token i compute attention over j
for (int i = 0; i < nTokens; i++){
vector<double>scores(nTokens);
for(int j = 0; j < nTokens; j++){
// dot over slice [h*d_k ... (h+1)*d_k-1]
double sum = 0;
for(int t = 0; t < d_k; t++) {
int idx = h * d_k + t;
sum += Q[i][idx] * K[j][idx];
}
scores[j] = sum / sqrt(d_k);
}
auto attention1D = softmax( scores );
// multiply attention1D by corresponding slice (column) of V
for(int t = 0; t < d_k; t++) {
double sum = 0;
for(int k = 0; k < nTokens; k++){ //scan the column
int idx = h*d_k + k;
sum += attention1D[k] * V[k][idx];
}
head_outputs[h][i*d_k + t] = sum;
}
}
}
// concatenate heads: nTokens x dModel
matrixd concat(nTokens, vector<double>(dModel, 0));
for(int i = 0; i < nTokens; i++)
for(int h=0; h < nHeads; h++)
for(int t = 0; t < d_k; t++)
concat[i][h*d_k + t] = head_outputs[h][i*d_k + t];
// muliply by WO to give final output
auto y = matmul(concat, WO);
return y;
}
// ---------------------------- Transformer Encoder Class ---------------
TransformerEncoder::TransformerEncoder(int embedding_dim, int num_heads,
int ff_dim)
{
dModel = embedding_dim;
nHeads = num_heads;
d_ff = ff_dim; // feed-forward network dimension
d_k = dModel / nHeads;
mha = new MultiHeadAttention(dModel, nHeads);
}
matrixd TransformerEncoder::mhAttention(const matrixd &X)
{
return mha->computeAttention( X );
}
// add & norm
matrixd TransformerEncoder::addNnorm(const matrixd &A, const matrixd &B)
{
auto x = addMat(A, B); // add two matrices
int n = x.size(); // rows
int m = x[0].size(); // cols
matrixd y = x; // output same size as x
// normalize the result
double epsilon = 1e-5;
for (int i = 0; i < n; i++) {
double sum = 0; // sum of one row
double std = 0; //sigma_i square
for (int j = 0; j < m; j++)
sum += x[i][j];
double mean = sum / m; // mu_i, mean of i-th row
sum = 0;
for (int j = 0; j < m; j++) {
double diff = x[i][j] - mean;
sum += diff * diff;
}
std = sum / m;
for (int j = 0; j < m; j++) {
double xd = (x[i][j] - mean) / sqrt(std + epsilon);
y[i][j] = xd; // gamma = 1, beta = 0;
}
}
return y; // final output of Add & norm
}
// Feed forward network
matrixd TransformerEncoder::FeedForward(const matrixd& x,
const matrixd& w1, const matrixd& w2)
{
matrixd z = x; // output same size as x
auto A = matmul(x, w1);
matrixd y = A; // same matrix size
int n = A.size();
int m = A[0].size();
for (int i = 0; i < n; i++)
for(int j = 0; j < m; j++)
y[i][j] = f(A[i][j]); // f is an activation function
z = matmul(y, w2); // y x w2
return z; // output of FeedForward
}
|
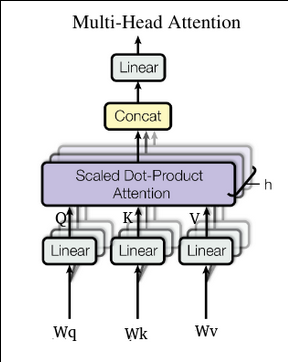 |
// testEncoder.cpp -- a main program for testing a transformer encoder
// http://forejune.co/cuda/
#include <iostream>
#include <iomanip>
#include "util.h"
#include "transformer.h"
using namespace std;
int main()
{
srand(time (0));
string sentence = "The waves crashed forcefully against the shore!";
// Tokenization
ifstream ifs;
char fname[] = "t.txt";
ifs.open( fname );
if (!ifs.is_open()) {
cerr << "Unable to open file " << fname << endl;
exit( 1 );
}
Tokenizer tokenizer( ifs );
unordered_map<string, int> dictionary;
dictionary = tokenizer.getTokensWords();
cout << "=== Tokenization ===" << endl;
printDictionary( dictionary );
getchar();
vector<int> tokens = tokenizer.tokenize(sentence);
cout << "\n=== Sentence Tokenization ===" << endl;
cout << "Original sentence:\n\t " << sentence << "\n\n";
cout << "Tokenization Results:\n";
cout << "Tokens: [";
for (size_t i = 0; i < tokens.size(); ++i) {
cout << tokens[i];
if (i < tokens.size() - 1) cout << ", ";
}
cout << "]\n";
getchar();
// Create embeddings
const int dModel = 8;
int totalTokens = tokenizer.get_nTokens();
cout << "\nVocabulary size: " << totalTokens;
cout << "\nEmbedding dimension: " << dModel << "\n";
Embedding embedding_layer(totalTokens, dModel);
matrixd embeddings = embedding_layer.embed(tokens);
cout << "\nToken Embeddings (" << embeddings.size() << " x " << dModel << "):\n";
printMatrix( embeddings );
getchar();
// Add positional encoding
const int MAX_SEQ_LENGTH = 16;
PositionalEncoding pos_encoding(MAX_SEQ_LENGTH, dModel);
matrixd pe = pos_encoding.getPE();
// add positional encoding to embeddings
matrixd embeddings_with_pos = pos_encoding.addPE(embeddings);
cout << "\nPositional Encodings:\n";
printMatrix( pe );
getchar();
cout << "\nEmbeddings with Positional Encoding:\n";
int rows = embeddings_with_pos.size();
int cols = embeddings_with_pos[0].size();
for (int i = 0; i < rows; i++) {
cout << "Token " << i << ": [";
for (int j = 0; j < cols; ++j) {
cout << fixed << setw(6) << setprecision(2) << embeddings_with_pos[i][j];
if (j < cols-1) cout << ", ";
}
cout << "]\n";
}
getchar();
// Pass through transformer encoder
int embedDimension = embedding_layer.get_embedDim();
int d_ff = 128;
TransformerEncoder transformer_encoder(embedDimension, 8, d_ff);
cout << "\n=== Transformer Processing ===\n";
cout << "Passing through transformer encoder layer...\n";
matrixd y = transformer_encoder.mhAttention(embeddings_with_pos);
cout << "\nMUltihead Attention Output (After Linear):\n";
printMatrix( y );
getchar();
matrixd y1 = transformer_encoder.addNnorm(embeddings_with_pos, y);
cout << "\nMUltihead Attention After Add & Norm:\n";
printMatrix( y1 );
getchar();
cout << "\nMUltihead Attention After Feedforward:\n";
matrixd W1, W2;
initMatrix(W1, dModel, d_ff);
initMatrix(W2, d_ff, dModel);
matrixd y2 = transformer_encoder.FeedForward(y1, W1, W2);
printMatrix( y2 );
matrixd y3 = transformer_encoder.addNnorm(y1, y2);
cout << "\nFeedforward data after Add & Norm:\n";
printMatrix( y3 );
getchar();
// Decode back to text
string decoded = tokenizer.detokenize(tokens);
cout << "\nDecoded tokens: " << decoded << "\n";
return 0;
}
|
Makefile:
PROG = testEncoder #source codes SRCS = $(PROG).cpp #substitute .cpp by .o to obtain object filenames OBJS = $(SRCS:.cpp=.o) util.o transformer.o #$@ evaluates to the target $(PROG): $(OBJS) g++ -o $@ $(OBJS) $(OBJS): g++ -c -std=c++20 $*.cpp clean: rm $(OBJS) $(PROG) |