Tokenization, Embedding, Positional Encoding,
Multi-head Attention and Sublayers of an AI
Transformer in C/C++
Materials available at: http://forejune.co/cuda/
Recap
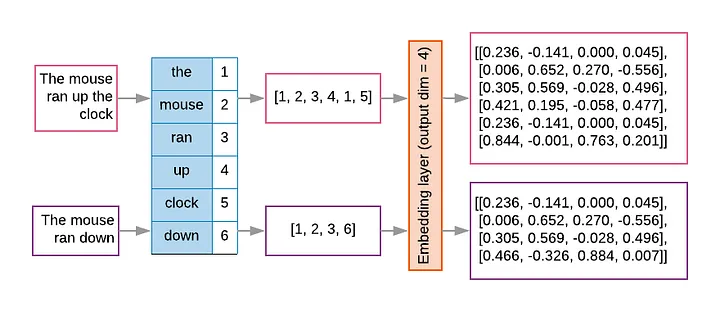
Example:
- A vocabulary has 10,000 tokens,
- Each embedding has 300 dimensions
- The embedding matrix is 10,000 x 300
class Tokenizer
{
private:
// unordered_map stores data in unique key-value pairs
unordered_map<string, int> words; //words with index
unordered_map<int, string> wordIndex; //indexing words
int nTokens; // number of words (tokens)
public:
Tokenizer(ifstream &fs)
{
string token;
vector<string> tokens;
// Read tokens (words) one by one, delimited by whitespace
int k = 0;
words["[UNK]"] = k; //unknown token
wordIndex[k] = "UNK]";
k++;
while (fs >> token) {
if (!words.contains(token)){
words[token] = k;
wordIndex[k] = token;
k++;
}
}
nTokens = words.size();
}
// Change a vector of tokens back to text
string detokenize(const vector<int>& tokenIDs)
{
string str;
for (int i = 0; i < tokenIDs.size(); i++) {
if (wordIndex.find(tokenIDs[i]) != wordIndex.end()) {
str += wordIndex[tokenIDs[i]];
// add a delimiter
if (i < tokenIDs.size() - 1 && wordIndex[tokenIDs[i+1]] != "!")
str += " ";
}
}
return str;
}
.....
};
|
typedef vector<vector<double>> matrixd;
class Embedding
{
private:
int nTokens; // number of words
int dim; // embedding dimension
matrixd em_matrix; // embedding matrix;
public:
Embedding(int sequence_length, int embeddingDimension)
{
nTokens = sequence_length;
dim = embeddingDimension;
// initialize embeddings as an nTokens x dim matrix with certain random values
initMatrix(em_matrix, nTokens, dim);
}
// create embedding matrix with tokenIDs
matrixd embed(const vector<int>& tokenIDs)
{
matrixd embeddings;
embeddings.reserve(tokenIDs.size()); // set capacity of embeddings vector
for(int i = 0; i < tokenIDs.size(); i++) {
if (tokenIDs[i] >= 0 && tokenIDs[i] < nTokens)
embeddings.push_back(em_matrix[tokenIDs[i]]);
else
// Out-of-dictionary tokens
embeddings.push_back(vector<double>(dim, 0.0));
}
return embeddings;
}
.....
};
|
Transformer
- Transformer architecture
left ~ encoder, right ~ decoder - Totally 6 identical layers
- Nx means the block with loop arrow repeating N times
- Each layer has sublayers,
(Multi-Head Attention, Feed Forward ...) - Encoder maps an input sequence
x = (x1,x2, ....,, xn) to
a continuous representation z = (z1,z2, ....,, zn)
- Generates an output sequence
(y1,y2, ....,, ym)
of symbols one element at a time - If x is input to a sub-layer and Fs(x) isthe output.
The quantities will be ''Add & Norm":Output of ''Add & Norm" = Normalization ( Fs(x) + x )
|
|
|
- which token comes first, second, ...
- relative distance between tokens
- directions (left vs. right context)
a dog bites a man = a man bites a dog
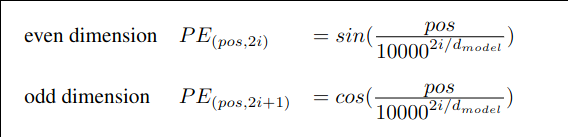
-
i = 0, 1, ..., dmodel/ 2
2i and 2i+1 are dimensions
pos is the position of the token
Positional encoding would let the transformer know where each token is in the sequence
Characteristics:
- Each position gets a unique encoding vector
- Allows model easily learn relative positions
- Values are bounded
- The values are deterministic and fixed
class PositionalEncoding
{
private:
int maxTokens; // maximum sequence length
int dModel; // embedding dimension
matrixd PE; // positional_encodings matrix;
public:
PositionalEncoding(int max_seq_length, int embedding_dimension)
{
maxTokens = max_seq_length;
dModel = embedding_dimension;
PE.resize(maxTokens, vector |

|
- generate text by sampling from the probability distribution
- perform statistical tasks such as classification
- calculate perplexity ("surprise")
a lower perplexity score implies less surprised
a high perplexity indicates the model struggles with the data
-
For a vector of real numbers z = (z1, z2, ...., zn)
The safe softmax method calculates instead
max = maximum element in vector
// softmax activation function, 1D input vector vector |
y = x W + b where x = input vector (or matrix of token embeddings) W = weight matrix b = bias vector Example: linear in multi-head attention(Q, K, V): Q = X x WQ, K = X x WK, V = X x WV Y = C x Wo, C = concatenated attention output Linear Layers mix features across dimensions e.g. C x Wo mix features from various heads They are efficient on GPUs/TPUs
|
|
A crucial layer combining a residual connection (Add)
(adding the input back to the sublayer's output) with Layer Normalization (Norm) to
stabilize training.
Add means add a residual connection:
Let F(x) = output of sublayer with input x
Add(x, F(x)) = x + F(x)
Norm means layer normalization:
 Initially, we can choose γ = 1, β = 0
Initially, we can choose γ = 1, β = 0
matrixd addNnorm(const matrixd &A, const matrixd &B)
{
auto x = addMat(A, B);
int n = x.size(); // rows
int m = x[0].size(); // cols
matrixd y = x; //output same size as x
double epsilon = 1e-5;
for (int i = 0; i < n; i++) {
double sum = 0; // sum of one row
double std = 0; //sigma_i square
for (int j = 0; j < m; j++)
sum += x[i][j];
double mean = sum / m; // mu_i, mean of i-th row
sum = 0;
for (int j = 0; j < m; j++) {
double diff = x[i][j] - mean;
sum += diff * diff;
}
std = sum / m;
for (int j = 0; j < m; j++) {
double xd = (x[i][j] - mean) / sqrt(std + epsilon);
y[i][j] = xd; // gamma = 1, beta = 0;
}
}
return y; // final output of Add & norm
}
If the FFN output were passed through a non-linear activation function:
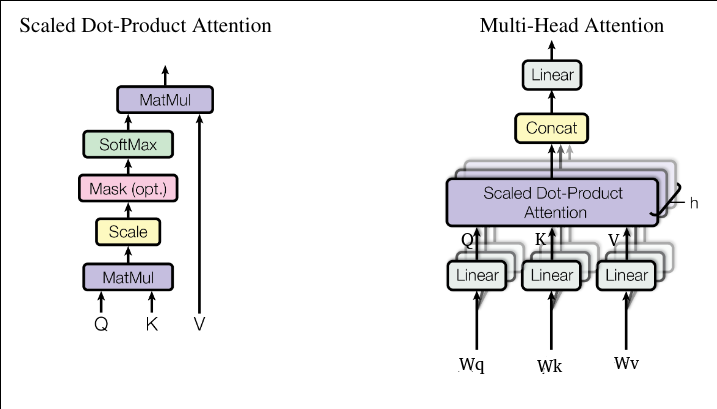
Scaled Dot-Product Attention
masking -- discard some non-text special tokens
class MultiHeadAttention { private: int dModel; int nHeads; int d_k; // dimension per head // weights: combine Q,K,V projections as separate matrices // (d_model x d_model) matrixd WQ, WK, WV, WO; public: MultiHeadAttention(int dm, int nh) { dModel = dm; nHeads = nh; d_k = dModel / nHeads; initMatrix(WQ, dModel, dModel); initMatrix(WK, dModel, dModel); initMatrix(WV, dModel, dModel); initMatrix(WO, dModel, dModel); } // input nTokens x dModel //matrixd forward(const matrixd &X) matrixd multiHeadAttention(const matrixd &X) { // X contains the embeddings, WQ ... are weight matrices auto Q = matmul(X, WQ); auto K = matmul(X, WK); auto V = matmul(X, WV); int nTokens = X.size(); // cancat outputs of heads matrixd head_outputs; // each head: nTokens x d_k head_outputs.assign(nHeads, vector<double>(dModel, 0)); for (int h = 0; h < nHeads; h++){ // for each token i compute attention over j for (int i = 0; i < nTokens; i++){ vector<double>scores(nTokens); for(int j = 0; j < nTokens; j++){ // dot over slice [h*d_k ... (h+1)*d_k-1] double sum = 0; for(int t = 0; t < d_k; t++) { int idx = h * d_k + t; sum += Q[i][idx] * K[j][idx]; } scores[j] = sum / sqrt(d_k); } auto attention1D = softmax( scores ); // multiply attention1D by corresponding slice (column) of V for(int t = 0; t < d_k; t++) { double sum = 0; for(int k = 0; k < nTokens; k++){ //scan the column int idx = h*d_k + k; sum += attention1D[k] * V[k][idx]; } head_outputs[h][i*d_k + t] = sum; } } } // concatenate heads: nTokens x dModel matrixd concat(nTokens, vector<double>(dModel, 0)); for(int i = 0; i < nTokens; i++) for(int h=0; h < nHeads; h++) for(int t = 0; t < d_k; t++) concat[i][h*d_k + t] = head_outputs[h][i*d_k + t]; // muliply by WO to give final output auto y = matmul(concat, WO); return y; } };Feed Forward Self-attention allows tokens to exchange information with other tokens, but by itself it is largely linear and focused on where to look. The feed-forward sublayer is to independently process and transform the information at each individual position, after it has been mixed with context from other positions by the Attention mechanism Analogy: A token ~ a person in a meeting Attention ~ listening to everyone else FFN ~ thinking privately and updating your own understanding For an input vector xi = (xi0, xi1, xi2, ...., xim)T representing one token's embeddings with dimension m = dmodel (xi0 is the bias) FFN(xi) = W2 σ(W1 xi) Weight matrix W1 expands the dimension (e.g. dff = 4dmodel) σ is a non-linear activation function (e.g. ReLU( z ) = max(0, z) ) Weight matrix W2 projects back to the model the dimension dmodel ~ MLP with one hidden layer, with a nonlinear activation function for hidden layer and a linear activation function (identical) for the output layer for the compatibility with the residual connections (Add) xout = x + FFN(x)

- The residual would mix linear and non-linear spaces
- The identity path would be distorted
- The gradient flow would be worse
We could organize the embeddings into an n x dmodel matrix
n = number of tokens
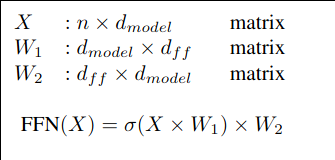
matrixd FeedForward(const matrixd& x, const matrixd& w1, const matrixd& w2)
{
matrixd z = x; // output same size as x
auto A = matmul(x, w1);
matrixd y = A; // same matrix size
int n = A.size();
int m = A[0].size();
for (int i = 0; i < n; i++)
for(int j = 0; j < m; j++)
y[i][j] = f(A[i][j]); // f is an activation function
z = matmul(y, w2);
return z; // output of FeedForward
}
|