Barrier Problem and Tiled Matrix Multiplication in CUDA
Barrier Problem
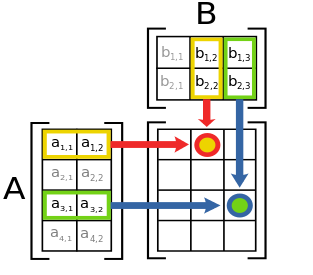
Simple Matrix Multiplication
|
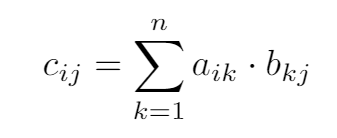 c12 = a11b12 + a12b22
M x N 4 x 2
N x L 2 x 3
---------- ------------
M x L 4 x 3
c12 = a11b12 + a12b22
M x N 4 x 2
N x L 2 x 3
---------- ------------
M x L 4 x 3
|
CUDA Multi-Threads
A block contains one or more threads,
and a grid contains one or more blocks.
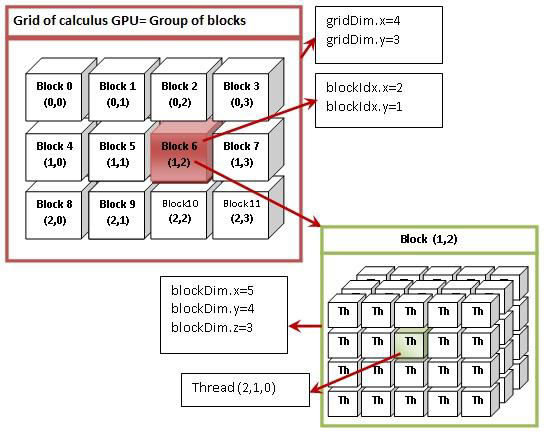 threadIdx.x = 1; threadIdx.y = 2; threadIdx.z = 0;
threadIdx.x = 1; threadIdx.y = 2; threadIdx.z = 0;
//matMultiply.cu
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
using namespace std;
const double MAX_ERR = 1e-5;
const int M = 64;
const int N = 62;
const int L = 64;
const int maxBlock = 1024;//max. # of thread in a block: 32x32
const double sqr2 = 1.4142135623730950488016887242;
__global__ void matMul(double *C, double *A, double *B)
{
double sum = 0.0;
int i = threadIdx.y + blockIdx.y * blockDim.y; //row
int j = threadIdx.x + blockIdx.x * blockDim.x; //col
for ( int k = 0; k < N; k++ )
sum = sum + A[i*N+k] * B[k*L+j];
C[i*L+j] = sum;
}
void checkError ( double *m, int nRows, int nCols )
{
for ( int i = 0; i < nRows; i++ ) {
for ( int j = 0; j < nCols; j++ ){
double x = *(m+i*nCols+j);
if ( abs ( x - 2.0 * N ) > MAX_ERR ) {
printf("\nError: %d, %d: %4.2f\n", i, j, x);
return;
}
}
}
printf("\nPASSED: %4.2f\n", *m);
}
int main()
{
double A[M][N], B[N][L], C[M][L];
double *dA, *dB, *dC;
for (int i = 0; i < M ; i++)
for (int j = 0; j < N; j++)
A[i][j] = sqr2;
for (int i = 0; i < N; i++)
for (int j = 0; j < L; j++)
B[i][j] = sqr2 ;
int aSize1 = sizeof( A );
int aSize2 = sizeof( B );
int aSize3 = sizeof( C );
bzero((char *) C, aSize3);
cudaMalloc((void **)&dA, aSize1);
cudaMalloc((void **)&dB, aSize2);
cudaMalloc((void **)&dC, aSize3);
//Transfer data from main memory (CPU) to GPU memory
cudaMemcpy(dA, A, aSize1, cudaMemcpyHostToDevice);
cudaMemcpy(dB, B, aSize2, cudaMemcpyHostToDevice);
cudaMemcpy(dC, C, aSize3, cudaMemcpyHostToDevice);
dim3 threadsPerBlock(M, L);
dim3 blocksPerGrid(1, 1);
if (M*L > maxBlock){
threadsPerBlock.x = 32;
threadsPerBlock.y = 32;
blocksPerGrid.x = ceil(L/32.0);
blocksPerGrid.y = ceil(M/32.0);
}
matMul<<< blocksPerGrid,threadsPerBlock>>>(dC, dA, dB);
cudaDeviceSynchronize();
// Transfer data back to host memory
cudaMemcpy(C, dC, aSize3, cudaMemcpyDeviceToHost);
checkError( &C[0][0], M, L );
cudaFree( dA );
cudaFree( dB );
cudaFree( dC );
return 0;
}
|
Each thread gives a pair of (i, j)
Each (i, j) pair is indexing the element C[i,j]
Totally MxL threads work in parallel.
Each thread calculates a sum.
|
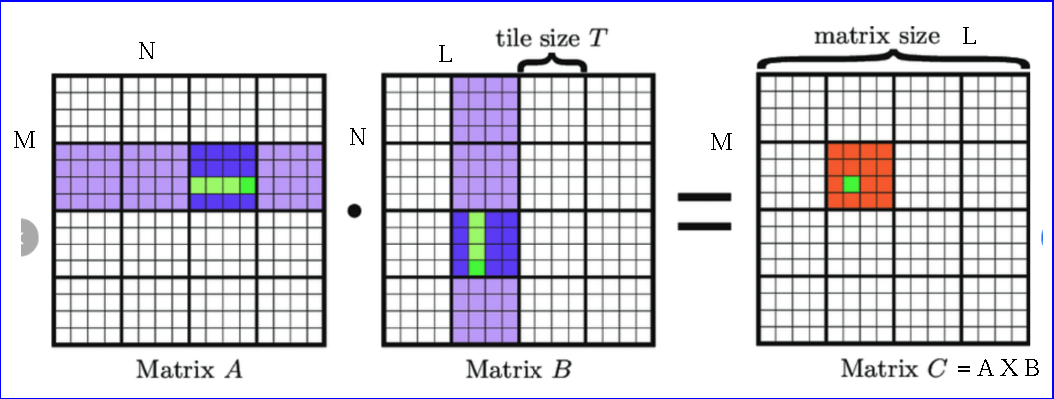
Tiled Matrix Multiplication

|

|
Divide data into tiles ~ blocks
Load the data of a tile into shared memory
and perform operations
- In the example, tile (block) 4x4
- Tile data of A and B are loaded in shared memories.
- A tile (block) is handled by a block of threads in parallel.
- A thread within a block (tile) calculates a dot product of the two submatrices
- Different thread blocks have their own separate shared memory.
- Each block's shared memory is private and independent.
- Multiple blocks execute the same kernel code concurrently
without interferring with each other's shared memory usage.
|
Grid dimension =
L/T X M/T
|
//tiledMatMultiply.cu
__global__ void matMul(double *C, double *A, double *B, int nTiles)
{
//Declare arrays in shared memory
__shared__ double sA[tileWidth][tileWidth];
__shared__ double sB[tileWidth][tileWidth];
int i = threadIdx.y + blockIdx.y * tileWidth; //row
int j = threadIdx.x + blockIdx.x * tileWidth; //col
int local_i = threadIdx.y; //index within a tile (shared memory)
int local_j = threadIdx.x;
double sum = 0.0;
//looping through the tiles
for (int t = 0; t < nTiles; ++t) {
// Load tiles into shared memory
if (i < M && (t * tileWidth + local_j) < N)
sA[local_i][local_j] = A[i*N + t * tileWidth + local_j];
else
sA[local_i][local_j] = 0.0;
if (j < L && (t * tileWidth + local_i) < N)
sB[local_i][local_j] = B[(t*tileWidth + local_i) * L + j];
else
sB[local_i][local_j] = 0.0;
//Wait until all threads within block (tile) have executed __syncthreads()
__syncthreads();
// Perform the matrix multiplication on the tile
for (int k = 0; k < tileWidth; ++k)
sum = sum + sA[local_i][k] * sB[k][local_j];
// Wait until each thread within the block (tile) has finished
// calculating its sum before loading the next tile
__syncthreads();
}
//save the result to matrix C
if (i < M && j < L )
C[i*L+j] = sum;
}
....
int main()
{
......
dim3 threadsPerBlock(tileWidth, tileWidth);//block size, a tile ~ block
dim3 blocksPerGrid(ceil((float)L/tileWidth), ceil((float)M/tileWidth));
//number of tiles in a row of A or a column of B
int nTiles = ceil((float)N / tileWidth);
matMul<<< blocksPerGrid,threadsPerBlock>>>(dC, dA, dB, nTiles);
......
}
|
e.g. tileWidth = 4
e.g. (i, j) = (6, 6)
(local_i, local_j) = (2, 1)
e.g. t = 2
|
Tiled Dot Product of Two Vectors
//dotProduct.cu
#include <stdio.h>
#include <stdlib.h>
using namespace std;
const double MAX_ERR = 1e-5;
const int N = 10000;
const double sqr2 = 1.4142135623730950488016887242;
__global__ void dotProduct(double *C, double *A, double *B)
{
double sum = 0.0;
for ( int k = 0; k < N; k++ )
sum = sum + A[k] * B[k];
C[0] = sum;
}
void checkError ( double *m )
{
if ( abs ( *m - 2.0 * N ) > MAX_ERR ) {
printf("\nError!\n");
return;
}
printf("\nPASSED: %6.2f\n", *m);
}
int main()
{
double A[N], B[N], C[1];
double *dA, *dB, *dC;
for (int i = 0; i < N; i++)
A[i] = sqr2;
for (int i = 0; i < N; i++)
B[i] = sqr2 ;
int aSize1 = sizeof( A );
int aSize2 = sizeof( B );
int aSize3 = sizeof( C );
cudaMalloc((void **)&dA, aSize1);
cudaMalloc((void **)&dB, aSize2);
cudaMalloc((void **)&dC, aSize3);
//Transfer data from main memory (CPU) to GPU memory
cudaMemcpy(dA, A, aSize1, cudaMemcpyHostToDevice);
cudaMemcpy(dB, B, aSize2, cudaMemcpyHostToDevice);
dotProduct<<< 1,1>>>(dC, dA, dB);
cudaDeviceSynchronize();
// Transfer data back to host memory
cudaMemcpy(C, dC, aSize3, cudaMemcpyDeviceToHost);
checkError( &C[0] );
cudaFree( dA );
cudaFree( dB );
cudaFree( dC );
return 0;
}
|
//tileddotProduct.cu
const int tileWidth = 1024;
__global__ void dotProduct(double *C, double *A, double *B)
{
__shared__ double tile[tileWidth];
int tid = threadIdx.x + blockIdx.x * blockDim.x; //thread id
int local_tid = threadIdx.x;//local thread id (within a block)
//totally tileWidth local_tid's
//Each thread calculating its own sum of products
double sum = 0.0;
// Looping through tiles
int distance = gridDim.x * blockDim.x;
for (int k = tid; k < N; k += distance)
sum += A[k] * B[k];
// Saving each thread's sum in shared memory
tile[local_tid] = sum;
__syncthreads();
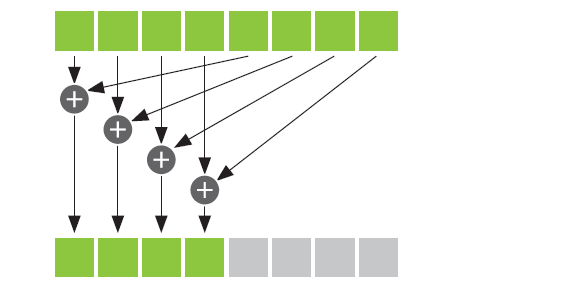
// Reduction within the block
for (int stride = blockDim.x / 2; stride > 0; stride /= 2) {
if (local_tid < stride)
tile[local_tid] += tile[local_tid + stride];
__syncthreads();
}
// Saving the block's partial sum in C array
if (local_tid == 0)
C[blockIdx.x] = tile[0];
}
int main()
{
double A[N], B[N];
int nBlocks = ceil ( (float) N / tileWidth ); //number of blocks
double C[nBlocks];
....
//tileWidth = number of threads in a block
dotProduct<<< nBlocks,tileWidth>>>(dC, dA, dB);
....
// Obtain the result on the host by summing partial results
for (int i = 1; i < nBlocks; i++)
C[0] += C[i];
checkError( &C[0] );
....
}
|
|
