Bitonic Sort in CUDA
Bitonic Sequence
A sequence a0, a1, ...... ,an-1 is bitonic if
it first monotonically increases and then monotonically decreases:
a0 ≤ a1 ≤ .... ≤ ak
ak ≥ ak+1 ≥ .... ≥ an-1
e.g. 8, 10, 14, 20, 30, 45, 40, 36, 28, 15, 2
 or it first monotonically decreases and then monotonically increases:
e.g. 9, 8, 3, 2, 4, 6, 7
or it first monotonically decreases and then monotonically increases:
e.g. 9, 8, 3, 2, 4, 6, 7
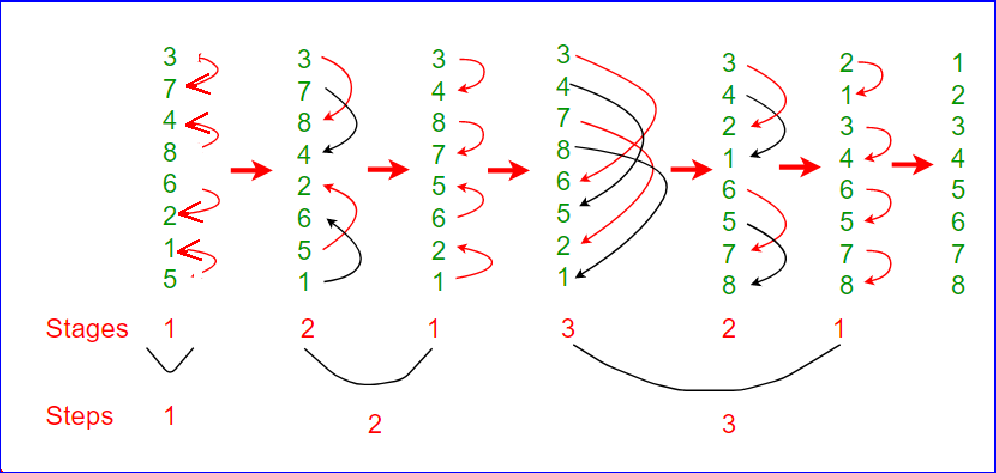
Bitonic Sort
and the other in descending order
Example: Sort sequence: 3 7 4 8 6 2 1 5
- start with segment length = 2
sort in ascending order sort in descending order

C/C++ Implementation
//BTsort.cpp
#include <iostream>
#include <algorithm>
using namespace std;
const int N = 16;
void sort(int a[], int start, int len, int distance, bool ascending)
{
for (int i = start; i < start + len - distance; i++)
if ((ascending && a[i] > a[i + distance]) ||
(!ascending && a[i] < a[i + distance]))
swap(a[i], a[i + distance]);
}
void bitonicSort(int a[], int n)
{
//sort the numbers, len = length of segment: 2, 4, 8, ...
for (int len = 2; len <= n; len *= 2) {
for (int start = 0; start < n; start += len) {
//sort segment 0 ascedning, segment 1 descending, 2 ascedning...
bool ascending = ((start / len) % 2 == 0);
//distance = distance between sorted elements, e.g.
//at steps 1, len = 2, distance = 1, iterate for loop once
// steps 2, len = 4, distance = 2, then 1, iterate for loop twice
for (int distance = len / 2; distance > 0; distance /= 2)
sort(a, start, len, distance, ascending);
}
}
}
void print(int a[])
{
int i;
if ( N <= 16 )
for (i = 0; i < N; i++)
cout << a[i] << " ";
else
for (i = 0; i < N; i += N/16)
cout << a[i] << " ";
cout << "\n";
}
int main()
{
int seed = static_cast<int>(time(0));
srand(seed);
int *a = (int *)malloc(N*sizeof(int));
for ( int i = 0; i < N; i++)
a[i] = rand() % 900;
if ( N <= 16 ) {
cout << "Before sorting:\n";
print( a );
}
// Ensure n is a power of 2 for bitonic sort
if ((N & (N - 1)) != 0) {
cerr << "Array size must be a power of 2.\n";
return -1;
}
bitonicSort(a, N);
cout << "Sorted array:\n";
print( a );
cout << "\n";
free ( a );
return 0;
}
|
For sorting random numbers:
bitonic sort :
To form a sorted sequence of length n from two sorted sequences of length n/2,
we need log(n) stages.
T(n) = log(n) + T(n/2)
O( n (log n)2)
heap sort : Θ(n log n)
quick sort : Θ(n log n)
merge sort : Θ(n log n)
one thread sorting a pair; n/2 threads working simultaneusly
CUDA Implementation using one thread
__device__ void swap(int *x, int *y)
{
int temp = *x;
*x = *y;
*y = temp;
}
__global__ void sort(int a[], int start, int len, int distance, bool ascending)
{
....
swap(&a[i], &a[i + distance]);
}
void bitonicSort(int a[], int n)
{
int *da;
int aSize = n * sizeof( int );
cudaMalloc(&da, aSize);
cudaMemcpy(da, a, aSize, cudaMemcpyHostToDevice);
....
sort<<<1, 1>>>(da, start, len, distance, ascending);
cudaDeviceSynchronize();
....
cudaMemcpy(a, da, aSize, cudaMemcpyDeviceToHost);
cudaFree(da);
}
|
__global__ void sort(int a[], int start, int len, int distance, bool ascending)
{
int i = threadIdx.x + blockDim.x * blockIdx.x; //thread id
if ( i >= start && i < start + len - distance )
if ((ascending && a[i] > a[i + distance]) ||
(!ascending && a[i] < a[i + distance]))
swap(&a[i], &a[i + distance]);
}
void bitonicSort(int a[], int n)
{
.....
int nThreads = 256; //number of threads in a block
int nBlocks = ceil((float) n / nThreads); //number of blocks
for (...) {
for (...) {
..
sort<<< nBlocks, nThreads>>>(da, start, len, distance, ascending);
}
}
....
}
|