|
|
|
|
|
C/C++
#include <stdio.h> #include <stdlib.h> using namespace std; const int M = 4; const int N = 3; const int L = 4; void dotProduct(double *C,double *A,double *B,int i,int j) { double sum = 0.0; for ( int k = 0; k < N; k++ ) sum = sum + A[i*N+k] * B[k*L+j]; C[i*L+j] = sum; } void printMat ( double *m, int nRows, int nCols ) { for ( int i = 0; i < nRows; i++ ) { printf("\n"); for ( int j = 0; j < nCols; j++ ) printf("%3.2f\t", *(m+i*nCols+j) ); } } int main() { //4x3 mat double A[][3] = {{0.866,-0.5,0}, {0.5,0.866,0}, {0,0,1},{0,0,1}}; //3x4 mat double B[][4] = {{0.5,-0.866,0,0}, {0.866,0.5,0,0},{0,0,1,1}}; double C[M][L]; for (int i = 0; i < M; i++) for(int j = 0; j < L; j++) dotProduct((double *)C,(double *)A, (double *)B,i,j); printMat( &A[0][0], M, N ); printf("\n-------------------------------"); printMat( &B[0][0], N, L ); printf("\n-------------------------------"); printMat( &C[0][0], M, L ); return 0; }CUDA
__global__ void dotProduct(...) .... double C[M][L]; double *dA, *dB, *dC; int aSize1 = sizeof( A ); int aSize2 = sizeof( B ); int aSize3 = sizeof( C ); cudaMalloc((void **)&dA, aSize1); cudaMalloc((void **)&dB, aSize2); cudaMalloc((void **)&dC, aSize3); //Transfer data from main memory (CPU) to GPU memory cudaMemcpy(dA, A, aSize1, cudaMemcpyHostToDevice); cudaMemcpy(dB, B, aSize2, cudaMemcpyHostToDevice); for (int i = 0; i < M; i++) for(int j = 0; j < L; j++) dotProduct<<<1,1>>>(dC, dA, dB, i, j); cudaDeviceSynchronize(); // Transfer data back to host memory cudaMemcpy(C, dC, aSize3, cudaMemcpyDeviceToHost); ..... cudaFree( dA ); cudaFree( dB ); cudaFree( dC ); return 0; }Higher Dimensions
const double MAX_ERR = 1e-6; const int M = 32; const int N = 30; const int L = 32; const double sqr2 = 1.4142135623730950488016887242; void checkError ( double *m, int nRows, int nCols ) { for ( int i = 0; i < nRows; i++ ) { for ( int j = 0; j < nCols; j++ ){ if ( abs ( *(m+i*nCols+j) - 2.0 * N ) > MAX_ERR ) { printf("\nError!\n"); return; } } } printf("\nPASSED: %4.2f\n", *m); } int main() { double A[M][N], B[N][L], C[M][L]; double *dA, *dB, *dC; for (int i = 0; i < M ; i++) for (int j = 0; j < N; j++) A[i][j] = sqr2; for (int i = 0; i < N; i++) for (int j = 0; j < L; j++) B[i][j] = sqr2; .... checkError ( (double *)C, M, L); }Multi-Threads
1. At the physical level, 32 threads are bundled as a thread warp 2. All the threads execute the same statement at any time except when branching 3. At the logical level, a block contains one or more threads, and a grid contains one or more blocks.//using one block only __global__ void dotProduct(double *C, double *A, double *B) { double sum = 0.0; int i = threadIdx.y; //row int j = threadIdx.x; //col for ( int k = 0; k < N; k++ ) sum = sum + A[i*N+k] * B[k*L+j]; C[i*L+j] = sum; } int main() { ..... dim3 threadsPerBlock(M, L); dim3 blocksPerGrid(1, 1); dotProduct<<< blocksPerGrid,threadsPerBlock>>>(dC, dA, dB); .... } threadIdx.x = 1; threadIdx.y = 2; threadIdx.z = 0;
Higher Dimensions
const int M = 120; const int N = 35; const int L = 140; const int maxBlock = 1024; //max. # of thread in a block: 32x32 ..... if (M*L > maxBlock){ threadsPerBlock.x = 32; threadsPerBlock.y = 32; blocksPerGrid.x = ceil(L/32.0); blocksPerGrid.y = ceil(M/32.0); }
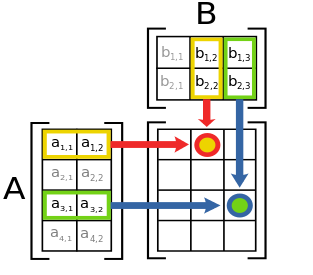
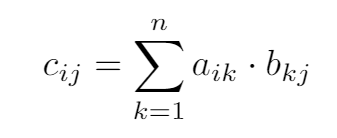 c12 = a11b12 + a12b22
M x N 4 x 2
N x L 2 x 3
---------- ------------
M x L 4 x 3
c12 = a11b12 + a12b22
M x N 4 x 2
N x L 2 x 3
---------- ------------
M x L 4 x 3