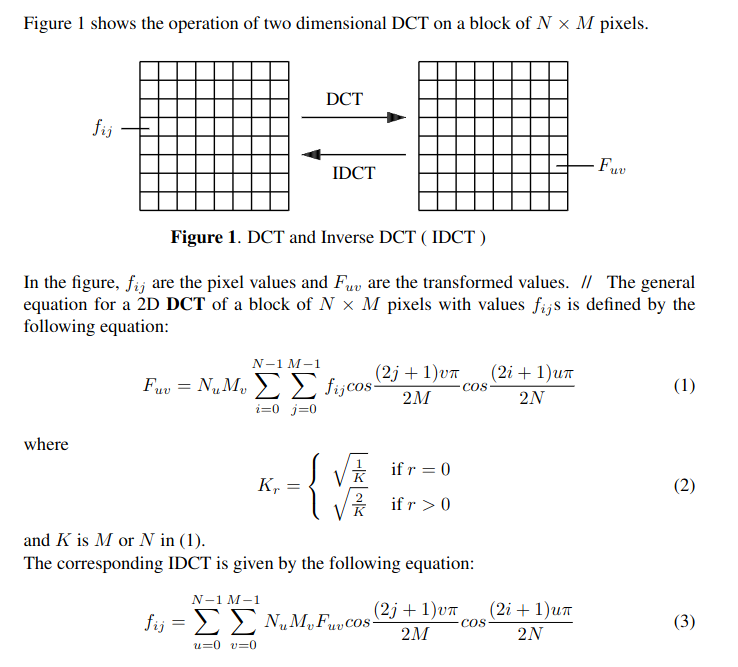
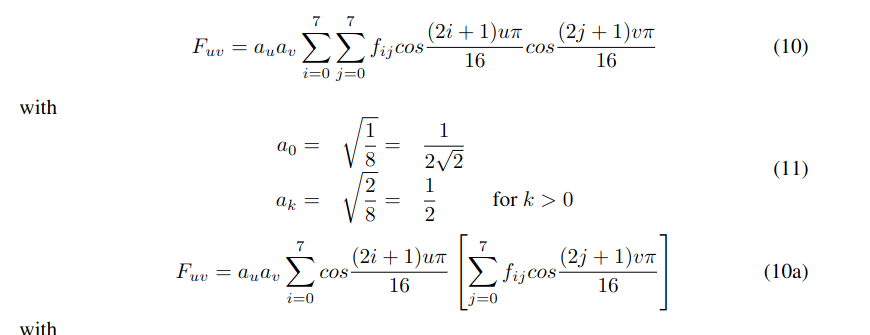
Number of calucations ~ N2
Fast DCT
Break down the summation into stages. Number of calucations ~ N log N rather than N2



 The cosine functions can be expressed in terms of each other.
The cosine functions can be expressed in terms of each other.
 In the calculations we often have this form
c = a + b
d = a - b
Can be represented by a flow graph:
In the calculations we often have this form
c = a + b
d = a - b
Can be represented by a flow graph:
 Flow graph of Butterfly Computation
If we include the constants ak in our calculations of yk and let
Ck = ckak = ck/2 = cos(kθ)/2 for k ≥ 1 (θ = π/16)
C0 = 1/√2
Note that C4 = cos(π/4)/2 = 1/(2√2)
We arrive at the following flow-graph:
Flow graph of Butterfly Computation
If we include the constants ak in our calculations of yk and let
Ck = ckak = ck/2 = cos(kθ)/2 for k ≥ 1 (θ = π/16)
C0 = 1/√2
Note that C4 = cos(π/4)/2 = 1/(2√2)
We arrive at the following flow-graph:

|
|
Without loss of generality, let us consider 16-bit integers
e.g. x = 2.75 (= 21 + 2-1 + 2-2)
Imagine there's a binary point at the right side of bit 0 of a 16-bit integer.
bit position: 15 9 8 7 6 5 4 3 2 1 0
x: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 . 1 1
To retain the information of the fractional part, we can left-shift
the whole number by 8 bits:
bit position: 15 9 8 7 6 5 4 3 2 1 0
x': 0 0 0 0 0 0 1 0.1 1 0 0 0 0 0 0
value of x' is 29 + 27 + 26 = 704
(x' = 2.75 * 256)
If we right-shift x' by 8 bits, we get 2 -- effectively truncating the number.
In most applications, rounding is preferred, which can be
achieved by adding 0.5 to the original value:
i.e. adding 0.5x256 = 128 to x' :
bit position: 15 9 8 7 6 5 4 3 2 1 0
x': 0 0 0 0 0 0 1 0.1 1 0 0 0 0 0 0
0.5: 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
x'': 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0 0
when we right-shift x'' by 8 bits, we obtain our desired value 3.
In general, we can transform real positive numbers to integers by multiplying
the real numbers by 2n; rounding effect is achieved by adding the
value 2n−1 to the results before shifting them right n bits.
Integer-arithmetic Implementation of Fast DCT
/*
fdctInt.cpp
An implementation of 8x8 DCT and IDCT for video compression.
32-bit integer-arithmetic is assumed.
For DCT operation:
dct ( int *X, int *Y );
X is the input pointing to an 8x8 array of samples; values must be within [0, 255]
Y is the output pointing to an 8x8 array of DCT coefficients.
For IDCT operation:
idct ( int *Y, int *X );
Y is the input pointing to an 8x8 array of DCT coefficients.
X is the output pointing to an 8x8 array of sample values.
*/
#include <string.h>
#include <stdio.h>
#include <math.h>
using namespace std;
#define PI 3.141592653589
const short shift = 10; //10 bits precision for fixed-point arithmetic
const short shift1 = 2 * shift; //at the final stage, values have been shifted twice
const int fac = 1 << shift ; //multiply all constants by 2^10 ( = 1024 )
const int delta = 1 << (shift-1); //for rounding adjustment ~ 0.5x2^10
const int delta1 = 1 << (shift1-1); //for final rounding adjustment ~ 0.5x2^20
const double a = PI / 16.0; //angle theta
//DCT constants; use integer-arithmetic.
const int c0 = (int) ( 1 / sqrt ( 2 ) * fac );
const int c1 = (int) ( cos ( a ) / 2 * fac );
const int c2 = (int) ( cos ( 2*a ) / 2 * fac );
const int c3 = (int) ( cos ( 3*a ) / 2 * fac );
const int c4 = (int) ( cos ( 4*a ) / 2 * fac );
const int c5 = (int) ( cos ( 5*a ) / 2 * fac );
const int c6 = (int) ( cos ( 6*a ) / 2 * fac );
const int c7 = (int) ( cos ( 7*a ) / 2 * fac );
/*
DCT function.
Input: X, array of 8x8, containing data with values in [0, 255].
Ouput: Y, array of 8x8 DCT coefficients.
*/
void dct(int *X, int *Y)
{
int i, j, j1, k;
int x[8], x1[8], m[8][8];
/*
Row transform
i-th row, k-th element
*/
for (i = 0, k = 0; i < 8; i++, k += 8) {
for (j = 0; j < 8; j++)
x[j] = X[k+j]; //data for one row
for (j = 0; j < 4; j++) { //first stage transform, see flow-graph
j1 = 7 - j;
x1[j] = x[j] + x[j1];
x1[j1] = x[j] - x[j1];
}
x[0] = x1[0] + x1[3]; //second stage transform
x[1] = x1[1] + x1[2];
x[2] = x1[1] - x1[2];
x[3] = x1[0] - x1[3];
x[4] = x1[4];
x[5] = ((x1[6] - x1[5]) * c0 + delta ) >> shift;//after multip,add delta (rounding)
x[6] = ((x1[6] + x1[5]) * c0 + delta ) >> shift;//shift-right to undo 'x fac' to line up
x[7] = x1[7]; // binary points of all x[i]
m[i][0] = (x[0] + x[1]) * c4; //upper-half of third (final) stage
m[i][4] = (x[0] - x[1]) * c4;
m[i][2] = x[2] * c6 + x[3] * c2;
m[i][6] = x[3] * c6 - x[2] * c2;
x1[4] = x[4] + x[5]; //lower-half of third stage
x1[5] = x[4] - x[5];
x1[6] = x[7] - x[6];
x1[7] = x[7] + x[6];
m[i][1] = x1[4] * c7 + x1[7] * c1; //lower-half of fourth (final) stage
m[i][7] = x1[7] * c7 - x1[4] * c1;
m[i][5] = x1[5] * c3 + x1[6] * c5;
m[i][3] = x1[6] * c3 - x1[5] * c5;
} //for i
/*
At this point, coefficients of each row ( m[i][j] ) has been multiplied by 2^10.
We can undo the multiplication by << 10 here before doing the vertical transform.
However, as we are using int variables, which are 32-bit to do multiplications, we
can tolerate another multiplication of 2^10. So we delay our undoing until the end
of the vertical transform and we undo all left-shift operations by shifting
the results right 20 bits ( i.e. << 2 * 10 ).
*/
// Column transform
for (i = 0; i < 8; i++) { //eight columns
//consider one column
for (j = 0; j < 4; j++) { //first-stage operation
j1 = 7 - j;
x1[j] = m[j][i] + m[j1][i];
x1[j1] = m[j][i] - m[j1][i];
}
//second-stage operation
x[0] = x1[0] + x1[3];
x[1] = x1[1] + x1[2];
x[2] = x1[1] - x1[2];
x[3] = x1[0] - x1[3];
x[4] = x1[4];
//undo one shift for x[5], x[6] to avoid overflow
x1[5] = (x1[5] + delta) >> shift;
x1[6] = (x1[6] + delta) >> shift;
x[5] = (x1[6] - x1[5]) * c0;
x[6] = (x1[6] + x1[5]) * c0;
x[7] = x1[7];
m[0][i] = (x[0] + x[1]) * c4; //upper-half of third (final) stage, see flow-graph
m[4][i] = (x[0] - x[1]) * c4;
m[2][i] = ( x[2] * c6 + x[3] * c2 ) ;
m[6][i] = ( x[3] * c6 - x[2] * c2 );
x1[4] = x[4] + x[5]; //lower-half of third stage
x1[7] = x[7] + x[6];
x1[5] = x[4] - x[5];
x1[6] = x[7] - x[6];
m[1][i] = x1[4] * c7 + x1[7] * c1; //lower-half of fourth stage
m[5][i] = x1[5] * c3 + x1[6] * c5;
m[3][i] = x1[6] * c3 - x1[5] * c5;
m[7][i] = x1[7] * c7 - x1[4] * c1;
} // for i
//we have left-shift (multiplying constants) twice
for ( i = 0; i < 8; ++i ) {
for ( j = 0; j < 8; ++j ) {
*Y++ = ( m[i][j] + delta1 ) >> shift1; //round the value by adding delta
}
}
}
/*
Implementation of idct() is to reverse the operations of dct().
We first do vertical transform and then horizontal; this is easier
for debugging as the operations are just the reverse of those in dct();
of course, it works just as well if you do the horizontal transform first.
So in this implementation, the first stage of idct() is the final stage of dct()
and the final stage of idct() is the first stage of dct().
*/
void idct(int *Y, int *X)
{
int j1, i, j;
int x[8], x1[8], m[8][8], y[8];
//column transform
for ( i = 0; i < 8; ++i ) {
for (j = 0; j < 8; j++)
y[j] = Y[i+8*j];
//print_x ( y );
//getchar();
x1[4] = y[1] * c7 - y[7] * c1; //lower-half final stage of dct
x1[7] = y[1] * c1 + y[7] * c7;
x1[6] = y[3] * c3 + y[5] * c5;
x1[5] = -y[3] * c5 + y[5] * c3;
x[4] = ( x1[4] + x1[5] ); //lower-half of third stage of dct
x[5] = ( x1[4] - x1[5] );
x[6] = ( x1[7] - x1[6] );
x[7] = ( x1[7] + x1[6] );
x1[0] = ( y[0] + y[4] ) * c4; //upper-half of third (final) stage of dct
x1[1] = ( y[0] - y[4] ) * c4;
x1[2] = y[2] * c6 - y[6] * c2;
x1[3] = y[2] * c2 + y[6] * c6;
x[0] = ( x1[0] + x1[3] ); //second stage of dct
x[1] = ( x1[1] + x1[2] );
x[2] = ( x1[1] - x1[2] );
x[3] = ( x1[0] - x1[3] );
//x[4], x[7] no change
x1[5] = ((x[6] - x[5]) * c0 + delta ) >> shift;//after multiplication,add delta for rounding
x1[6] = ((x[6] + x[5]) * c0 + delta ) >> shift;//shift-right to undo 'x fac' to line up x[]s
x[5] = x1[5];
x[6] = x1[6];
for (j = 0; j < 4; j++) { //first stage transform of dct
j1 = 7 - j;
m[j][i] = (x[j] + x[j1] );
m[j1][i] = (x[j] - x[j1] );
}
} //for i
//row transform
for ( i = 0; i < 8; i++ ) {
for (j = 0; j < 8; j++)
y[j] = m[i][j] ; //data for one row
x1[4] = y[1] * c7 - y[7] * c1;
x1[7] = y[1] * c1 + y[7] * c7;
x1[6] = y[3] * c3 + y[5] * c5;
x1[5] = -y[3] * c5 + y[5] * c3;
x[4] = ( x1[4] + x1[5] ); //lower-half of third stage
x[5] = ( x1[4] - x1[5] );
x[6] = ( x1[7] - x1[6] );
x[7] = ( x1[7] + x1[6] );
x1[0] = ( y[0] + y[4] ) * c4;
x1[1] = ( y[0] - y[4] ) * c4;
x1[2] = y[2] * c6 - y[6] * c2;
x1[3] = y[2] * c2 + y[6] * c6;
//undo one shift for x[5], x[6] to avoid overflow
x1[5] = (x[5] + delta) >> shift;
x1[6] = (x[6] + delta) >> shift;
x[5] = (x1[6] - x1[5]) * c0;
x[6] = (x1[6] + x1[5]) * c0;
//x[4], x[7] no change
x[0] = ( x1[0] + x1[3] ); //second stage transform
x[1] = ( x1[1] + x1[2] );
x[2] = ( x1[1] - x1[2] );
x[3] = ( x1[0] - x1[3] );
for (j = 0; j < 4; j++) { //first stage transform
j1 = 7 - j;
m[i][j] = (x[j] + x[j1]);
m[i][j1] = (x[j] - x[j1]);
}
}
//we have left-shift (multiplying constants) twice
for ( i = 0; i < 8; ++i ) {
for ( j = 0; j < 8; ++j ) {
*X++ = ( m[i][j] + delta1 ) >> shift1; //round by adding delta
}
}
}
void print_block( int *X )
{
int k = 0;
for ( int i = 0; i < 8; ++i ){
printf("\n");
for ( int j = 0; j < 8; ++j ) {
printf("%d, ", X[k++] );
}
}
}
int main()
{
int X[64], Y[64], i, j, k;
//some sample data
k = 0;
for ( i = 0; i < 8; ++i )
for ( j = 0; j < 8; ++j )
X[k++] = ( 3 * i *j + j + 1 );
printf("\nOriginal Data:");
printf("\n ------------------");
print_block ( X );
dct( X, Y );
printf("\n\nData after dct:");
print_block ( Y );
bzero ( X, 256 ); //clear X
idct ( Y, X );
printf("\n\nData recovered by idct:");
printf("\n ------------------");
print_block ( X );
printf("\n");
return 0;
}
|
In CUDA
Using One Thread
_global__ void dct(int *X, int *Y, int *C)
{
.....
int c0, c1, c2, c3, c4, c5, c6, c7;
c0=C[0], c1=C[1], c2=C[2], c3=C[3], c4=C[4], c5=C[5], c6=C[6], c7=C[7];
.....
}
__global__ void idct(int *Y, int *X, int *C)
{
.....
int c0, c1, c2, c3, c4, c5, c6, c7;
c0=C[0], c1=C[1], c2=C[2], c3=C[3], c4=C[4], c5=C[5], c6=C[6], c7=C[7];
.....
}
int main()
{
.....
int C[] = {c0, c1, c2, c3, c4, c5, c6, c7};
.....
int *dX, *dY, *dC;
int aSize = 8 * 8 * sizeof(int);
int aSizeC = 8 * sizeof(int);
cudaMalloc(&dX, aSize);
cudaMalloc(&dY, aSize);
cudaMalloc(&dC, aSizeC);
// Copy data to device
cudaMemcpy(dX, X, aSize, cudaMemcpyHostToDevice);
cudaMemcpy(dC, C, aSizeC, cudaMemcpyHostToDevice);
// Define grid and block dimensions
dim3 blockDim(1, 1);
dim3 gridDim(1, 1);
.....
dct<<< 1, 1>>>(dX, dY, dC);
cudaDeviceSynchronize();
// Copy result back to host
cudaMemcpy(Y, dY, aSize, cudaMemcpyDeviceToHost);
.....
idct<<< 1, 1>>> (dY, dX, dC);
cudaDeviceSynchronize();
cudaMemcpy(X, dX, aSize, cudaMemcpyDeviceToHost);
.....
cudaFree(dX);
cudaFree(dY);
cudaFree(dC);
return 0;
}
|
A grid contains one or more blocks, and
a block contains one or more threads,
Shared Memory within a block 
|
/*
fdctInt.cu
*/
/*
DCT function.
Input: X, array of 8x8, containing data with values in [0, 255].
Ouput: Y, array of 8x8 DCT coefficients.
C[] is the array of cosine constants.
*/
__global__ void dct(int *X, int *Y, int *C)
{
int j1, k;
int x[8], x1[8]; //local variables
__shared__ int xt[8][8], xt1[8][8];
__shared__ int m[8][8];
__shared__ int c0, c1, c2, c3, c4, c5, c6, c7;
int tj = threadIdx.y;
int i = threadIdx.x;
if ( i == 0 && tj == 0 )
c0=C[0], c1=C[1], c2=C[2], c3=C[3], c4=C[4], c5=C[5], c6=C[6], c7=C[7];
__syncthreads();
k = i * 8;
xt[i][tj] = X[k+tj];
__syncthreads();
if ( tj < 4 ) {
j1 = 7 - tj;
xt1[i][tj] = xt[i][tj] + xt[i][j1];
xt1[i][j1] = xt[i][tj] - xt[i][j1];
}
__syncthreads();
x[0] = xt1[i][0] + xt1[i][3]; //second stage transform
x[1] = xt1[i][1] + xt1[i][2];
x[2] = xt1[i][1] - xt1[i][2];
x[3] = xt1[i][0] - xt1[i][3];
x[4] = xt1[i][4];
x[5] = ((xt1[i][6] - xt1[i][5]) * c0 + delta ) >> shift;//add delta for rounding,
x[6] = ((xt1[i][6] + xt1[i][5]) * c0 + delta ) >> shift;//shift-right to undo 'x fac' to
x[7] = xt1[i][7]; //line up binary points of all x[i]
__syncthreads();
m[i][0] = (x[0] + x[1]) * c4; //upper-half of third (final) stage, see flow-graph
m[i][4] = (x[0] - x[1]) * c4;
m[i][2] = x[2] * c6 + x[3] * c2;
m[i][6] = x[3] * c6 - x[2] * c2;
xt1[i][4] = x[4] + x[5]; //lower-half of third stage
xt1[i][5] = x[4] - x[5];
xt1[i][6] = x[7] - x[6];
xt1[i][7] = x[7] + x[6];
__syncthreads();
m[i][1] = xt1[i][4] * c7 + xt1[i][7] * c1; //lower-half of fourth ( final ) stage
m[i][7] = xt1[i][7] * c7 - xt1[i][4] * c1;
m[i][5] = xt1[i][5] * c3 + xt1[i][6] * c5;
m[i][3] = xt1[i][6] * c3 - xt1[i][5] * c5;
__syncthreads();
if ( tj < 4 ) {
j1 = 7 - tj;
xt1[i][tj] = m[tj][i] + m[j1][i];
xt1[i][j1] = m[tj][i] - m[j1][i];
}
__syncthreads();
if (tj == 0 ) {
x[0] = xt1[i][0] + xt1[i][3];
x[1] = xt1[i][1] + xt1[i][2];
x[2] = xt1[i][1] - xt1[i][2];
x[3] = xt1[i][0] - xt1[i][3];
x[4] = xt1[i][4];
//undo one shift for x[5], x[6] to avoid overflow
xt1[i][5] = (xt1[i][5] + delta) >> shift;
xt1[i][6] = (xt1[i][6] + delta) >> shift;
x[5] = (xt1[i][6] - xt1[i][5]) * c0;
x[6] = (xt1[i][6] + xt1[i][5]) * c0;
x[7] = xt1[i][7];
m[0][i] = (x[0] + x[1]) * c4; //upper-half of third (final) stage, see flow-graph
m[4][i] = (x[0] - x[1]) * c4;
m[2][i] = ( x[2] * c6 + x[3] * c2 ) ;
m[6][i] = ( x[3] * c6 - x[2] * c2 );
x1[4] = x[4] + x[5]; //lower-half of third stage
x1[7] = x[7] + x[6];
x1[5] = x[4] - x[5];
x1[6] = x[7] - x[6];
m[1][i] = x1[4] * c7 + x1[7] * c1;//lower-half of fourth stage
m[5][i] = x1[5] * c3 + x1[6] * c5;
m[3][i] = x1[6] * c3 - x1[5] * c5;
m[7][i] = x1[7] * c7 - x1[4] * c1;
}
__syncthreads(); //second-stage operation
Y[8*i+tj] = ( m[i][tj] + delta1 ) >> shift1; //rounding
__syncthreads();
}
__global__ void idct(int *Y, int *X, int *C)
{
int j1, i, j;
int x[8], x1[8], y[8];
__shared__ int c0, c1, c2, c3, c4, c5, c6, c7;
__shared__ int m[8][8];
c0=C[0], c1=C[1], c2=C[2], c3=C[3], c4=C[4], c5=C[5], c6=C[6], c7=C[7];
int tj = threadIdx.y;
i = threadIdx.x;
if ( i == 0 && tj == 0 ) {
c0=C[0], c1=C[1], c2=C[2], c3=C[3], c4=C[4], c5=C[5], c6=C[6], c7=C[7];
}
__syncthreads();
//column transform
for (j = 0; j < 8; j++)
y[j] = Y[i+8*j];
x1[4] = y[1] * c7 - y[7] * c1; //lower-half final stage of dct
x1[7] = y[1] * c1 + y[7] * c7;
x1[6] = y[3] * c3 + y[5] * c5;
x1[5] = -y[3] * c5 + y[5] * c3;
x[4] = ( x1[4] + x1[5] ); //lower-half of third stage of dct
x[5] = ( x1[4] - x1[5] );
x[6] = ( x1[7] - x1[6] );
x[7] = ( x1[7] + x1[6] );
x1[0] = ( y[0] + y[4] ) * c4; //upper-half of third ( final ) stage of dct
x1[1] = ( y[0] - y[4] ) * c4;
x1[2] = y[2] * c6 - y[6] * c2;
x1[3] = y[2] * c2 + y[6] * c6;
x[0] = ( x1[0] + x1[3] ); //second stage of dct
x[1] = ( x1[1] + x1[2] );
x[2] = ( x1[1] - x1[2] );
x[3] = ( x1[0] - x1[3] );
//x[4], x[7] no change
x1[5] = ((x[6] - x[5]) * c0 + delta ) >> shift; //add delta for rounding,
x1[6] = ((x[6] + x[5]) * c0 + delta ) >> shift; //shift-right to undo 'x fac'
//to line up x[]s
x[5] = x1[5];
x[6] = x1[6];
for (j = 0; j < 4; j++) { //first stage transform of dct
j1 = 7 - j;
m[j][i] = (x[j] + x[j1] );
m[j1][i] = (x[j] - x[j1] );
}
__syncthreads();
//row transform
for (j = 0; j < 8; j++)
y[j] = m[i][j] ; //data for one row
x1[4] = y[1] * c7 - y[7] * c1;
x1[7] = y[1] * c1 + y[7] * c7;
x1[6] = y[3] * c3 + y[5] * c5;
x1[5] = -y[3] * c5 + y[5] * c3;
x[4] = ( x1[4] + x1[5] ); //lower-half of third stage
x[5] = ( x1[4] - x1[5] );
x[6] = ( x1[7] - x1[6] );
x[7] = ( x1[7] + x1[6] );
x1[0] = ( y[0] + y[4] ) * c4;
x1[1] = ( y[0] - y[4] ) * c4;
x1[2] = y[2] * c6 - y[6] * c2;
x1[3] = y[2] * c2 + y[6] * c6;
//undo one shift for x[5], x[6] to avoid overflow
x1[5] = (x[5] + delta) >> shift;
x1[6] = (x[6] + delta) >> shift;
x[5] = (x1[6] - x1[5]) * c0;
x[6] = (x1[6] + x1[5]) * c0;
//x[4], x[7] no change
x[0] = ( x1[0] + x1[3] ); //second stage transform
x[1] = ( x1[1] + x1[2] );
x[2] = ( x1[1] - x1[2] );
x[3] = ( x1[0] - x1[3] );
for (j = 0; j < 4; j++) { //first stage transform, see flow-graph
j1 = 7 - j;
m[i][j] = (x[j] + x[j1]);
m[i][j1] = (x[j] - x[j1]);
}
__syncthreads();
//we have left-shift (multiplying constants) twice
for (j = 0; j < 8; j++)
X[i*8+j] = ( m[i][j] + delta1 ) >> shift1; //round by adding delta
}
int main()
{
int X[64], Y[64], i, j, k;
int C[] = {c0, c1, c2, c3, c4, c5, c6, c7};
//some sample data
k = 0;
for (i = 0; i < 8; ++i)
for (j = 0; j < 8; ++j)
X[k++] = (3 * i *j + j + 1);
int *dX, *dY, *dC;
int aSize = 8 * 8 * sizeof(int);
int aSizeC = 8 * sizeof(int);
cudaMalloc(&dX, aSize);
cudaMalloc(&dY, aSize);
cudaMalloc(&dC, aSizeC);
// Copy data to device
cudaMemcpy(dX, X, aSize, cudaMemcpyHostToDevice);
cudaMemcpy(dC, C, aSizeC, cudaMemcpyHostToDevice);
// Define grid and block dimensions
dim3 blockDim(8, 8);
dim3 gridDim(1, 1);
printf("\nOriginal Data:");
printf("\n ------------------");
print_block ( X );
dct<<< gridDim, blockDim>>>(dX, dY, dC);
cudaDeviceSynchronize();
// Copy result back to host
cudaMemcpy(Y, dY, aSize, cudaMemcpyDeviceToHost);
printf("\n\nData after dct:");
print_block ( Y );
bzero ( X, 256 ); //clear X
dim3 blockDim1(8, 1);
idct<<< gridDim, blockDim1>>> (dY, dX, dC);
cudaDeviceSynchronize();
cudaMemcpy(X, dX, aSize, cudaMemcpyDeviceToHost);
printf("\n\nData recovered by idct:");
printf("\n ------------------");
print_block ( X );
printf("\n");
cudaFree(dX);
cudaFree(dY);
cudaFree(dC);
return 0;
}
|
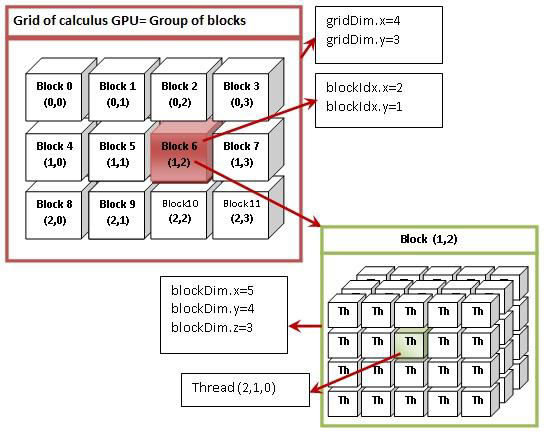 threadIdx.x = 1, threadIdx.y = 2, threadIdx.z = 0
threadIdx.x = 1, threadIdx.y = 2, threadIdx.z = 0