A Simple 8x8 Discrete Cosine Transform (DCT) in CUDA
Discrete Cosine Transform (DCT)
- A Fourier-like transform proposed by Ahmed et al. in 1974.
- Use only cosine functions as basis functions.
- Present the output in the frequency domain.
- Widely used in many engineer and science applications,
including the MPEG video compression
Macroblocks
- Macroblock ~ a region of 8 x 8 samples
- i.e. M = N = 8, Equation (3) becomes
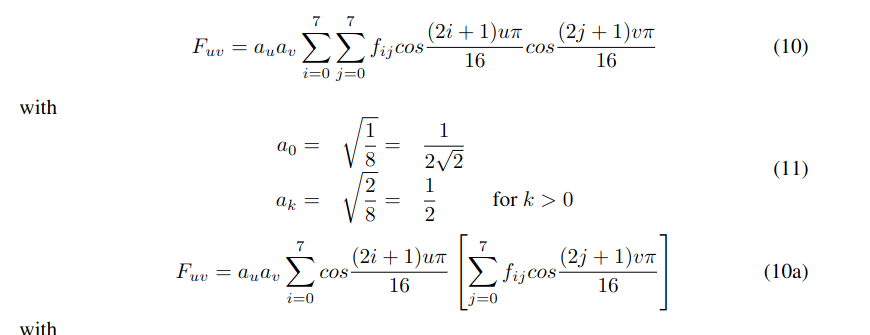
- The separability of i and j is important.
- We can arrange the fij values in an 8x8 matrix.
- For a given pair of (u, v), the cosine values could also be arranged in an 8x8 matrix.
| f00 | f01 | f02 | f03 | f04 | f05 | f06 | f07 | | f10 | f11 | f12 | f13 | f14 | f15 | f16 | f17 | | f20 | f21 | f22 | f23 | f24 | f25 | f26 | f27 | | f30 | f31 | f32 | f33 | f34 | f35 | f36 | f37 | | f40 | f41 | f42 | f43 | f44 | f45 | f46 | f47 | | f50 | f51 | f52 | f53 | f54 | f55 | f56 | f57 | | f60 | f61 | f62 | f63 | f64 | f65 | f66 | f67 | | f70 | f71 | f72 | f73 | f74 | f75 | f76 | f77 |
|
|
| C00 | C01 | C02 | C03 | C04 | C05 | C06 | C07 | | C10 | C11 | C12 | C13 | C14 | C15 | C16 | C17 | | C20 | C21 | C22 | C23 | C24 | C25 | C26 | C27 | | C30 | C31 | C32 | C33 | C34 | C35 | C36 | C37 | | C40 | C41 | C42 | C43 | C44 | C45 | C46 | C47 | | C50 | C51 | C52 | C53 | C54 | C55 | C56 | C57 | | C60 | C61 | C62 | C63 | C64 | C65 | C66 | C67 | | C70 | C71 | C72 | C73 | C74 | C75 | C76 | C77 |
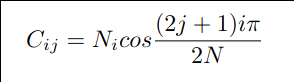
|
- [] term, sum over j: dot product of v-th row vector of f and v-th row vector of C
or row-v((f).column-v(CT)
- left term, sum over i: dot product of u-th column vector of f and u-th row vector of C
or row-u of C . column-u of f u
- So, in matrix form, we can express (10a) as
F = C f CT
- It turns out that C-1 = CT or CT C = I
CT F C = f
or
f = CT F C

- Sometimes DCT is referred to as Forward DCT in order to distingusih it from Inverse DCT (IDCT)
C/C++ Implementation
- Cosine values are often calculated offline
//genCosine.cpp
#include <iostream>
#include <iomanip>
#include <math.h>
using namespace std;
const double PI = 3.141592653589;
int main()
{
const int N = 8;
double CT[N][N];
double a[N];
a[0] = sqrt ( 1.0 / N );
for (int i = 1; i < N; ++i )
a[i] = sqrt ( 2.0 / N );
for ( int v = 0; v < N; ++v )
for ( int j = 0; j < N; ++j )
CT[j][v] =a[v] * cos((2*j+1)*v*PI/(2*N));
cout << fixed << setprecision(5);
for (int i = 0; i < N; i++){
cout << "\n";
for (int j = 0; j < N; j++)
cout << CT[i][j] << ", ";
}
cout << endl;
return 0;
}
|
- 8x8 DCT and IDCT in C/C++
/*
dct.cpp
A straight forward implementation of 8x8 DCT and IDCT.
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
using namespace std;
#define PI 3.141592653589
const int N = 8;
//cosine basis
const double C[N][N] =
{
0.35355, 0.49039, 0.46194, 0.41573, 0.35355, 0.27779, 0.19134, 0.09755,
0.35355, 0.41573, 0.19134, -0.09755, -0.35355, -0.49039, -0.46194, -0.27779,
0.35355, 0.27779, -0.19134, -0.49039, -0.35355, 0.09755, 0.46194, 0.41573,
0.35355, 0.09755, -0.46194, -0.27779, 0.35355, 0.41573, -0.19134, -0.49039,
0.35355, -0.09755, -0.46194, 0.27779, 0.35355, -0.41573, -0.19134, 0.49039,
0.35355, -0.27779, -0.19134, 0.49039, -0.35355, -0.09755, 0.46194, -0.41573,
0.35355, -0.41573, 0.19134, 0.09755, -0.35355, 0.49039, -0.46194, 0.27779,
0.35355, -0.49039, 0.46194, -0.41573, 0.35355, -0.27779, 0.19134, -0.09755
};
//input: f, output: F
void dct(double f[][N], double F[][N] )
{
double sum;
for ( int u = 0; u < N; ++u ) {
for ( int v = 0; v < N; ++v ) {
sum = 0.0;
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
sum += f[i][j] * C[i][u] * C[j][v];
F[u][v] = sum;
} //for v
} //for u
}
//input F; output f
void idct(double F[][N], double f[][N])
{
double sum;
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j ) {
sum = 0.0;
for (int u = 0; u < N; ++u )
for (int v = 0; v < N; ++v )
sum += F[u][v] * C[i][u] * C[j][v]; //for v
f[i][j] = sum;
} //for j
} //for j
}
void print_elements (short f[][N] )
{
for (int i = 0; i < N; ++i ){
printf("\n");
for (int j = 0; j < N; ++j )
printf ("%4d, ", f[i][j]);
}
}
void short2double(short f[N][N], double f_double[N][N])
{
for (int i = 0; i < N; ++i)
for(int j = 0; j < N; j++)
f_double[i][j] = (double) f[i][j];
}
void double2short (double F_double[N][N], short F[N][N])
{
for (int i = 0; i < N; i++)
for(int j = 0; j < N; j++)
F[i][j] = (short) (floor (F_double[i][j]+0.5)); //rounding
}
int main()
{
short f[N][N], F[N][N];
//try some values for testing
for (int i = 0; i < N; ++i )
for (int j = 0; j < N; ++j)
f[i][j] = i + j;
printf("\nOriginal sample values");
print_elements ( f );
printf("\n--------------------\n");
double f_double[N][N], F_double[N][N];
short2double(f, f_double);
dct(f_double, F_double); //performing DCT
double2short(F_double, F);
printf("\nCoefficients of DCT:");
print_elements ( F );
printf("\n--------------------\n");
idct (F_double, f_double); //performing IDCT
double2short(f_double, f);
printf("\nValues recovered by IDCT:");
print_elements ( f );
printf("\n");
}
|
CUDA Implementation
- Using One Thread
//input: f, output: F
__global__ void dct(double *f, double *F, const double *C )
{
double sum;
for ( int u = 0; u < N; ++u ) {
for ( int v = 0; v < N; ++v ) {
sum = 0.0;
for (int i = 0; i < N; i++)
for (int j = 0; j < N; j++)
sum += f[i*N+j] * C[i*N+u] * C[j*N+v];
F[u*N+v] = sum;
} //for v
} //for u
}
//input F; output f
__global__ void idct(double *F, double *f, const double *C)
{
double sum;
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j ) {
sum = 0.0;
for (int u = 0; u < N; ++u )
for (int v = 0; v < N; ++v )
sum += F[u*N+v] * C[i*N+u] * C[j*N+v]; //for v
f[i*N+j] = sum;
} //for j
} //for j
}
int main()
{
short f[N][N], F[N][N];
//try some values for testing
for (int i = 0; i < N; ++i )
for (int j = 0; j < N; ++j)
f[i][j] = i + j;
printf("\nOriginal sample values");
print_elements ( f );
printf("\n--------------------\n");
double f_double[N][N], F_double[N][N];
double *df, *dF, *dC;
int aSize = N * N * sizeof(double);
cudaMalloc(&df, aSize);
cudaMalloc(&dF, aSize);
cudaMalloc(&dC, aSize);
//Note: may use cudaMallocPitch() to create 2D array, but less convenient
short2double(f, f_double);
cudaMemcpy(df, f_double, aSize, cudaMemcpyHostToDevice);
cudaMemcpy(dC, C, aSize, cudaMemcpyHostToDevice);
dim3 blockDim(1, 1);
dim3 gridDim(1, 1);
dct<<< gridDim, blockDim>>>(df, dF, dC); //performing DCT
cudaDeviceSynchronize();
cudaMemcpy(F_double, dF, aSize, cudaMemcpyDeviceToHost);
double2short(F_double, F);
printf("\nCoefficients of DCT:");
print_elements ( F );
printf("\n--------------------\n");
idct<<< gridDim, blockDim>>> (dF, df, dC); //performing IDCT
cudaDeviceSynchronize();
cudaMemcpy(f_double, df, aSize, cudaMemcpyDeviceToHost);
double2short(f_double, f);
printf("\nValues recovered by IDCT:");
print_elements ( f );
printf("\n");
cudaFree(df);
cudaFree(dF);
cudaFree(dC);
}
|
- Using Multi-Threads
A grid contains one or more blocks, and
a block contains one or more threads,
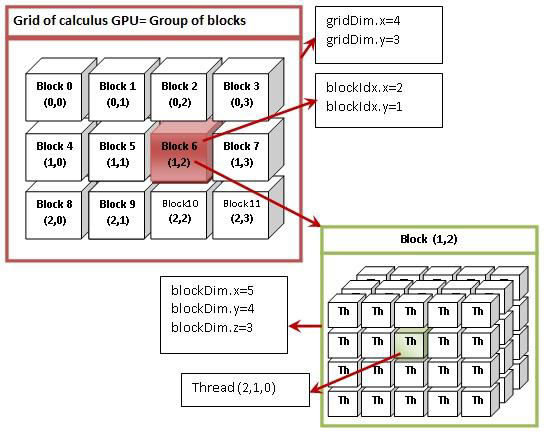
One thread to calcuate one sample.
Use one block, 64 threads to calcuate 64 samples in parallel.
|
__global__ void
dct(double *f, double *F, const double *C )
{
double sum;
int u = threadIdx.x; //Row index of output
int v = threadIdx.y; //Column index of output
.....
}
_global__ void
idct(double *F, double *f, const double *C)
{
double sum;
int i = threadIdx.x;
int j = threadIdx.y;
....
}
nt main()
{
....
dim3 blockDim(N, N);
dim3 gridDim(1, 1);
....
}
|
|
Fast DCT
Break down the summation into stages.
Number of calucations ~ N log N rather than N2