Arrays Addition in CUDA
C/C++
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <assert.h>
const int N = 10000000;
#define MAX_ERR 1e-6
void add(float *sum, float *a, float *b, int n)
{
for(int i = 0; i < n; i++)
sum[i] = a[i] + b[i];
}
int main()
{
float *a, *b, *sum;
int nbytes = sizeof(float) * N;
// Allocate memory
a = (float*)malloc(nbytes);
b = (float*)malloc(nbytes);
sum = (float*)malloc(nbytes);
// Initialize array
for(int i = 0; i < N; i++){
a[i] = 1.0;
b[i] = 2.0;
}
add(sum, a, b, N);
// Verification
for(int i = 0; i < N; i++){
assert(fabs(sum[i] - a[i] - b[i]) < MAX_ERR);
}
printf("sum[0] = %f\n", sum[0]);
printf("PASSED\n");
free(a);
free(b);
free(sum);
return 0;
}
|
|
CUDA
__global__
void add(float *sum, float *a, float *b, int n)
add<<<1,1>>>(sum, a, b, N);
|
Need to allocate memory in GPU (device) memory
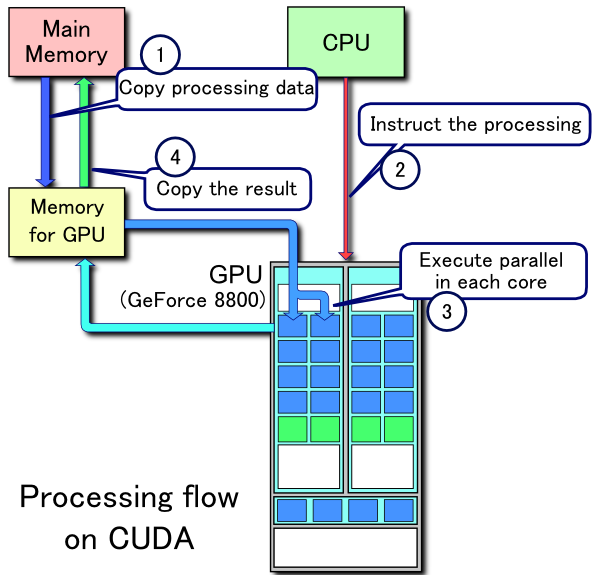
cudaMalloc(void **devPtr, size_t count);
cudaFree(void *devPtr);
e.g.
//Allocate GPU memory
int nbytes = sizeof(float) * N;
float *da;
cudaMalloc((void **) &da, nbytes);
//Transfer data from main memory (CPU) to GPU memory
cudaMemcpy(da, a, nbytes, cudaMemcpyHostToDevice);
add<<<1,1>>>(dsum, da, db, N);
// Transfer data back to host memory
cudaMemcpy(sum, dsum, nbytes, cudaMemcpyDeviceToHost);
Profiling Performance
$nvprof ./addArrays-cu
Parallel Operations
threads are grouped into thread blocks
thread blokcs are grouped into grids
Using one thread block, consisting of 256 threads
add<<<1,256>>>(dsum, da, db, N);
CUDA provides built-in variables for accessing thread information.
threadIdx.x : index of the thread within the block
blockDim.x : number of threads in the thread block
add<<<1,256>>>(dsum, da, db, N);
 int tid = threadIdx.x;
int stride = blockDim.x;
for(int i = tid; i < n; i += stride)
sum[i] = a[i] + b[i];
gridDim.x : number of blocks in the grid
Using multiple thread blocks, if each block contains 256 threads
#of thread blocks = ceil( N / 256 )
int blockSize = 256;
int nBlocks = (N + blockSize - 1) / blockSize;
add<<< nBlocks, blockSize >>>(dsum, da, db, N);
int tid = threadIdx.x;
int stride = blockDim.x;
for(int i = tid; i < n; i += stride)
sum[i] = a[i] + b[i];
gridDim.x : number of blocks in the grid
Using multiple thread blocks, if each block contains 256 threads
#of thread blocks = ceil( N / 256 )
int blockSize = 256;
int nBlocks = (N + blockSize - 1) / blockSize;
add<<< nBlocks, blockSize >>>(dsum, da, db, N);
 __global__ void add(float *sum, float *a, float *b, int n)
{
//thread id
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n)
sum[i] = a[i] + b[i];
}
__global__ void add(float *sum, float *a, float *b, int n)
{
//thread id
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n)
sum[i] = a[i] + b[i];
}