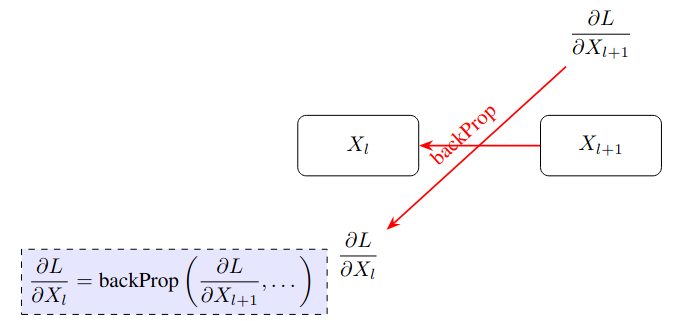
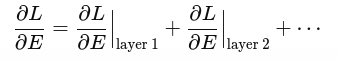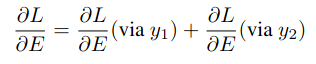// http://forejune.co/cuda
// transformer.cpp: Encoder-Decoder Transformer
#include <iostream>
#include <fstream>
#include <vector>
#include <string>
#include <unordered_map>
#include <cmath>
#include <random>
#include <algorithm>
#include <iomanip>
#include <cassert>
#include "util.h"
#include "transformer.h"
using namespace std;
// ------------------------ Tokenizer class --------------------------
// -------------------------------
// Default constructor
// -------------------------------
Tokenizer::Tokenizer()
{
nTokens = 0;
// Initialize special tokens first
addWord(PAD); // 0
addWord(UNK); // 1
addWord(BOS); // 2
addWord(EOS); // 3
addWord(SEP); // 4
}
// -------------------------------
// Build vocab from file
// -------------------------------
Tokenizer::Tokenizer(ifstream &fs) : Tokenizer()
{
string line;
while (getline(fs, line)) {
vector<string> tokens = split(line); //split(line);
for (int i = 0; i < tokens.size(); i++)
addWord(tokens[i]);
}
}
unordered_map<string, int> Tokenizer::getTokensWords()
{
return words;
}
vector<int> Tokenizer::tokenize(const string& str)
{
vector<int> ids;
vector<string> tokens = split(str);
for (int i = 0; i < tokens.size(); i++) {
string w = tokens[i];
if (words.find(w) != words.end())
ids.push_back(words[w]);
else
ids.push_back(words[UNK]);
}
return ids;
}
string Tokenizer::detokenize(const vector<int>& tokenIDs)
{
string words;
int n = tokenIDs.size();
for (int i = 0; i < n; i++) {
int id = tokenIDs[i];
if (wordIndex.find(id) == wordIndex.end())
continue;
string w = wordIndex[id];
// Skip special tokens (optional behavior)
if (w == "<PAD>" || w == "<BOS>" || w == "<EOS>")
continue;
words += w + " ";
}
return words;
}
int Tokenizer::get_nTokens() const
{
return nTokens;
}
unordered_map<int, string>Tokenizer::get_wordIndex()
{
return wordIndex;
}
//------------------ Embedding Class ------------------
Embedding::Embedding(int sequence_length, int embeddingDimension)
{
nTokens = sequence_length;
dim = embeddingDimension;
// initialize embeddings as an nTokensxdim matrix with certain random values
initMatrix(em_matrix, nTokens, dim);
}
// create embedding matrix with tokenIDs
matrixd Embedding::embed(const vector<int>& tokenIDs)
{
matrixd embeddings;
embeddings.reserve(tokenIDs.size()); // set capacity of embeddings vector
for(int i = 0; i < tokenIDs.size(); i++) {
if (tokenIDs[i] >= 0 && tokenIDs[i] < nTokens)
embeddings.push_back(em_matrix[tokenIDs[i]]);
else
// Out-of-dictionary tokens
embeddings.push_back(vector<double>(dim, 0.0));
}
return embeddings;
}
int Embedding::get_embedDim() const
{
return dim;
}
int Embedding::get_nTokens() const
{
return nTokens;
}
// optional
void Embedding::backProp(const vector<int>& tokenIDs,
const matrixd& dL_dX,
double eta)
{
int nt = tokenIDs.size();
for (int i = 0; i < nt; i++) {
int token = tokenIDs[i];
for (int j = 0; j < dim; j++)
em_matrix[token][j] -= eta * dL_dX[i][j];
}
}
// --------------------- Positional Encoding class ---------------
PositionalEncoding::PositionalEncoding(int max_seq_length, int embed_dimension)
{
maxTokens = max_seq_length;
dModel = embed_dimension;
PE.resize(maxTokens, vector<double>(dModel));
for (int pos = 0; pos < maxTokens; pos++) {
for (int i = 0; i < dModel/2; i++) {
PE[pos][2*i] = sin( pos / pow(10000, 2.0*i/dModel) );
PE[pos][2*i+1] = cos( pos / pow(10000, 2.0*i/dModel) );
}
}
}
void PositionalEncoding::extendPE(int new_maxTokens)
{
if (new_maxTokens <= maxTokens) return;
int oldMax = maxTokens;
maxTokens = new_maxTokens;
PE.resize(maxTokens, vector<double>(dModel, 0.0));
for (int pos = oldMax; pos < maxTokens; pos++) {
for (int i = 0; i < dModel; i += 2) {
double denom = pow(10000.0, (double)i / dModel);
PE[pos][i] = sin(pos / denom);
if (i + 1 < dModel)
PE[pos][i + 1] = cos(pos / denom);
}
}
}
// add positional encodings to embeddings
matrixd PositionalEncoding::addPE(const matrixd& embeddings)
{
int nTokens = embeddings.size();
int dim = embeddings[0].size();
assert(dim == dModel);
if (nTokens > maxTokens) {
extendPE(nTokens);
}
matrixd x = embeddings;
// scale before adding PE (optional)
double scale = sqrt(dModel);
for (int i = 0; i < nTokens; i++)
for (int j = 0; j < dModel; j++)
x[i][j] = embeddings[i][j] * scale + PE[i][j];
return x;
}
matrixd PositionalEncoding::getPE()
{
return PE;
}
// -------------------- Add & Norm Class---------------------------------
// constructor
AddnNorm::AddnNorm(int dModel)
{
gamma.assign(dModel, 1.0);
beta.assign(dModel, 0.0),
eps = 1e-5;
}
matrixd AddnNorm::forward (const matrixd &A, const matrixd &B)
{
matrixd x = addMat(A, B); // add two matrices
int n = x.size(); // rows
int m = x[0].size(); // cols
mean.resize( n );
var.resize( n );
Zhat.resize(n, vector<double>(m, 0));
matrixd Y(n, vector<double>(m));
// normalize the result
for (int i = 0; i < n; i++) {
double sum = 0; // sum of one row
var[i] = 0;
for (int j = 0; j < m; j++)
sum += x[i][j];
mean[i] = sum / m; // mu_i, mean of i-th row
sum = 0;
for (int j = 0; j < m; j++) {
double diff = x[i][j] - mean[i];
sum += diff * diff;
}
var[i] = sum / m;
for (int j = 0; j < m; j++) {
double xd = (x[i][j] - mean[i]) / sqrt(var[i] + eps); //epsilon);
Zhat[i][j] = xd;
Y[i][j] = gamma[j] * xd + beta[j];
}
}
return Y; // final output of Add & norm
}
// Assume forward already filled: Zhat, mean, var
AddNormGrad AddnNorm::backProp(const matrixd &X, const matrixd &dL_dY, double eta)
{
int nt = X.size();
int m = X[0].size();
matrixd dL_dZ(nt, vector<double>(m, 0.0));
matrixd dL_dZhat(nt, vector<double>(m, 0.0));
vector<double> dL_dGamma(m, 0.0); // gradient wrt gamma
vector<double> dL_dBeta(m, 0.0); // gradient wrt beta
// 1. Compute dL_dGamma and dL_dBeta for each token
for (int i = 0; i < nt; i++)
{
for (int j = 0; j < m; j++){
dL_dBeta[j] += dL_dY[i][j];
dL_dGamma[j] += dL_dY[i][j] * Zhat[i][j];
}
}
// 2. Backprop through LayerNorm (row-wise)
for (int i = 0; i < nt; i++)
{
double inv_sigma = 1.0 / sqrt(var[i] + eps);
// Step A: compute intermediate values
vector<double> dL_dZhat(m);
for (int j = 0; j < m; j++)
{
dL_dZhat[j] = dL_dY[i][j] * gamma[j];
}
double sum_dL_dZhat = 0.0;
double sum_dL_dZhat_zhat = 0.0;
for (int j = 0; j < m; j++)
{
sum_dL_dZhat += dL_dZhat[j];
sum_dL_dZhat_zhat += dL_dZhat[j] * Zhat[i][j];
}
// Final gradient
for (int j = 0; j < m; j++)
{
dL_dZ[i][j] = inv_sigma * (dL_dZhat[j] - sum_dL_dZhat / m
- Zhat[i][j] * sum_dL_dZhat_zhat / m);
}
}
// 3. Update parameters
for (int j = 0; j < m; j++)
{
gamma[j] -= eta * dL_dGamma[j];
beta[j] -= eta * dL_dBeta[j];
}
AddNormGrad grad;
grad.dL_dA = dL_dZ; // residual path
grad.dL_dB = dL_dZ; // sublayer path
return grad;
}
// Optional setters (to plug in forward results)
void AddnNorm::setCache(const matrixd& zhat, const vector<double>& m,
const vector<double>& v)
{
Zhat = zhat;
mean = m;
var = v;
}
// --------------------------- Feed Forward -----------------------------------
FeedForward::FeedForward(int dModel0, int d_ff0)
{
dModel = dModel0;
d_ff = d_ff0;
W1.resize(dModel, vector<double>(d_ff));
W2.resize(d_ff, vector<double>(dModel));
initMatrix(W1, dModel, d_ff);
initMatrix(W2, d_ff, dModel);
}
// ------------------------------
// Forward (for cache)
// ------------------------------
matrixd FeedForward::FFoutput(const matrixd &X)
{
Z = matmul(X, W1); // pre-activation
F1 = relu( Z ); // f(Z); F1 = f(XW1)
matrixd F2 = matmul(F1, W2); // F2 = F1 W2
return F2;
}
// ------------------------------
// Backprop
// ------------------------------
matrixd FeedForward::backProp(const matrixd &X, const matrixd &dL_dY, // dL/dF2
double eta)
{
// ---- W2 ----
matrixd dL_dF2 = dL_dY;
// dL/dW2 = F1^T * dL_dF2
matrixd F1T = transpose(F1);
matrixd dL_dW2 = matmul(F1T, dL_dF2);
// dL_dF1 = dL_dF2 * W2^T
matrixd W2T = transpose(W2);
matrixd dL_dF1 = matmul(dL_dF2, W2T);
// ---- find dL_dZ1 ----
matrixd fd_Z = relu_deriv(Z); // f_deriv(Z);
int rows = dL_dF1.size();
int cols = dL_dF1[0].size();
matrixd dL_dZ1 = dL_dF1; // same dimension
for (int i = 0; i < rows; i++)
for (int j = 0; j < cols; j++)
dL_dZ1[i][j] = dL_dF1[i][j] * fd_Z[i][j];
// ---- W1 ----
// dL/dW1 = X^T * dL/dZ1
matrixd XT = transpose(X);
matrixd dL_dW1 = matmul(XT, dL_dZ1);
// dL/dX = dL/dZ1 * W1^T
matrixd W1T = transpose(W1);
matrixd dL_dX = matmul(dL_dZ1, W1T);
// ---- Update weights ----
for (int i = 0; i < W2.size(); i++)
for (int j = 0; j < W2[0].size(); j++)
W2[i][j] -= eta * dL_dW2[i][j];
for (int i = 0; i < W1.size(); i++)
for (int j = 0; j < W1[0].size(); j++)
W1[i][j] -= eta * dL_dW1[i][j];
return dL_dX; // This becomes the dL_dY of next stage
}
// ------------------ MultiHeadAttention --------------------
MultiHeadAttention::MultiHeadAttention(int dim, int n)
{
dModel = dim;
nHeads = n;
d_k = dModel / nHeads;
WQ.resize(nHeads);
WK.resize(nHeads);
WV.resize(nHeads);
for (int h = 0; h < nHeads; h++) {
initMatrix(WQ[h], dModel, d_k);
initMatrix(WK[h], dModel, d_k);
initMatrix(WV[h], dModel, d_k);
}
initMatrix(WO, dModel, dModel);
}
void MultiHeadAttention::clearCache()
{
Qs.clear();
Ks.clear();
Vs.clear();
Ps.clear();
As.clear();
}
matrixd MultiHeadAttention::computeAttention(const matrixd &X_Q,
const matrixd &X_K, const matrixd &X_V, bool mask)
{
Qs.clear(); Ks.clear(); Vs.clear();
Ps.clear(); As.clear();
vector<matrixd> heads;
int nq = X_Q.size();
int nk = X_K.size();
for (int h = 0; h < nHeads; h++) {
matrixd Qh = matmul(X_Q, WQ[h]); // nq x d_k
matrixd Kh = matmul(X_K, WK[h]); // nk x d_k
matrixd Vh = matmul(X_V, WV[h]); // nk x d_k
matrixd S = matmul(Qh, transpose(Kh));
scaleMat(S, 1.0 / sqrt(d_k));
if (mask)
S = causalMask(S);
matrixd Ph = softmax(S); // row-wise
matrixd Ah = matmul(Ph, Vh); // nq x d_k
Qs.push_back(Qh);
Ks.push_back(Kh);
Vs.push_back(Vh);
Ps.push_back(Ph);
As.push_back(Ah);
heads.push_back(Ah);
}
// Concatenate heads
int n = heads[0].size();
matrixd concat(n, vector<double>(dModel, 0.0));
for (int h = 0; h < nHeads; h++)
for (int i = 0; i < n; i++)
for (int j = 0; j < d_k; j++)
concat[i][h * d_k + j] = heads[h][i][j];
// Final projection
matrixd H = matmul(concat, WO);
return H;
}
// backpropagation
MHA_Gradient MultiHeadAttention::backProp(
const matrixd &X_Q,
const matrixd &X_K,
const matrixd &X_V,
const matrixd &dL_dH,
double eta,
bool mask)
{
if (Ps.empty() || As.empty()) {
cout << "ERROR: MHA cache empty in backProp!" << endl;
exit(1);
}
int nt = X_Q.size();
double s = 1.0 / sqrt(d_k);
// =========================
// Step 1: concatenate heads
// =========================
matrixd A_cat(nt, vector<double>(dModel, 0.0));
for (int h = 0; h < nHeads; h++)
for (int i = 0; i < nt; i++)
for (int j = 0; j < d_k; j++)
A_cat[i][h*d_k + j] = As[h][i][j];
// =========================
// Step 2: gradients for WO
// =========================
matrixd dL_dWO = matmul(transpose(A_cat), dL_dH);
// Compute before updating WO
matrixd dL_dAcat = matmul(dL_dH, transpose(WO));
// =========================
// Step 3: initialize accumulators
// =========================
matrixd dL_dXQ(X_Q.size(), vector<double>(dModel, 0.0));
matrixd dL_dXK(X_K.size(), vector<double>(dModel, 0.0));
matrixd dL_dXV(X_V.size(), vector<double>(dModel, 0.0));
// =========================
// Step 4: per-head backprop
// =========================
for (int h = 0; h < nHeads; h++)
{
// ---- slice dA ----
matrixd dL_dA(nt, vector<double>(d_k));
for (int i = 0; i < nt; i++)
for (int j = 0; j < d_k; j++)
dL_dA[i][j] = dL_dAcat[i][h*d_k + j];
matrixd P = Ps[h];
matrixd V = Vs[h];
matrixd Q = Qs[h];
matrixd K = Ks[h];
// =====================
// A = P V
// =====================
matrixd dL_dP = matmul(dL_dA, transpose(V));
matrixd dL_dV = matmul(transpose(P), dL_dA);
// optional stabilization
//scaleMat(dL_dP, 1.0 / nt);
// =====================
// softmax backward
// =====================
matrixd dL_dS = softmax_derivative(dL_dP, P);
// apply mask if used
if (mask) {
for (int i = 0; i < nt; i++)
for (int j = i+1; j < nt; j++)
dL_dS[i][j] = 0.0;
}
// =====================
// S = (Q K^T) * s
// =====================
matrixd dL_dQ = matmul(dL_dS, K);
matrixd dL_dK = matmul(transpose(dL_dS), Q);
scaleMat(dL_dQ, s);
scaleMat(dL_dK, s);
// =====================
// Weight gradients
// =====================
matrixd dL_dWQ = matmul(transpose(X_Q), dL_dQ);
matrixd dL_dWK = matmul(transpose(X_K), dL_dK);
matrixd dL_dWV = matmul(transpose(X_V), dL_dV);
// =====================
// Input gradients (USE OLD WEIGHTS!)
// =====================
matrixd dXQ = matmul(dL_dQ, transpose(WQ[h]));
matrixd dXK = matmul(dL_dK, transpose(WK[h]));
matrixd dXV = matmul(dL_dV, transpose(WV[h]));
// accumulate across heads
dL_dXQ = addMat(dL_dXQ, dXQ);
dL_dXK = addMat(dL_dXK, dXK);
dL_dXV = addMat(dL_dXV, dXV);
// =====================
// Update weights after gradients
// =====================
updateWeight(WQ[h], dL_dWQ, eta);
updateWeight(WK[h], dL_dWK, eta);
updateWeight(WV[h], dL_dWV, eta);
}
// =========================
// Step 5: update WO
// =========================
updateWeight(WO, dL_dWO, eta);
// =========================
// return gradients
// =========================
MHA_Gradient grad;
grad.dL_dQ = dL_dXQ;
grad.dL_dK = dL_dXK;
grad.dL_dV = dL_dXV;
return grad;
}
// ---------- EncoderLayer --------------------
EncoderLayer::EncoderLayer(int d_model, int nHeads, int d_ff)
: mha(d_model, nHeads),
ffn(d_model, d_ff),
norm1(d_model),
norm2(d_model) {}
matrixd EncoderLayer::forward(const matrixd& input)
{
X = input;
mha.clearCache();
matrixd A1 = mha.computeAttention(X, X, X, true);
H1 = norm1.forward(X, A1);
matrixd A2 = ffn.FFoutput(H1);
H2 = norm2.forward(H1, A2);
return H2;
}
matrixd EncoderLayer::backProp(const matrixd& dL_dY, double eta)
{
// =========================
// Step 1: FFN block
// =========================
AddNormGrad g2 = norm2.backProp(H1, dL_dY, eta);
matrixd dL_dH1_res = g2.dL_dA;
matrixd dL_dFFN_in = g2.dL_dB;
matrixd dL_dH1_ffn = ffn.backProp(H1, dL_dFFN_in, eta);
matrixd dL_dH1 = addMat(dL_dH1_res, dL_dH1_ffn);
// =========================
// Step 2: MHA block
// =========================
AddNormGrad g1 = norm1.backProp(X, dL_dH1, eta);
matrixd dX_res = g1.dL_dA;
matrixd dL_dMHA = g1.dL_dB;
MHA_Gradient g_mha = mha.backProp(X, X, X, dL_dMHA, eta, false);
matrixd dL_dX_mha = addMat(g_mha.dL_dQ,
addMat(g_mha.dL_dK, g_mha.dL_dV));
matrixd dL_dX = addMat(dX_res, dL_dX_mha);
return dL_dX;
}
// ---------- OutputLayer ----------------------
OutputLayer::OutputLayer(int dim, int nv)
{
dModel = dim;
vocab_size = nv;
initMatrix(W, dModel, vocab_size);
}
// Forward: logits -> probabilities
matrixd OutputLayer::forward(const matrixd &X)
{
// X: (seq_len x dModel)
// output: (seq_len x vocab_size)
matrixd logits = matmul(X, W);
return softmax(logits);
}
// Backward: returns dL/dX
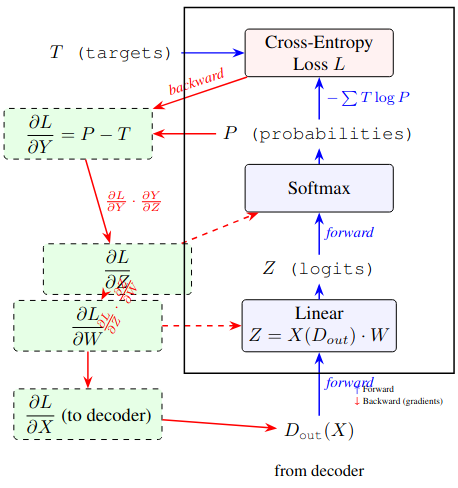
matrixd OutputLayer::backward(const matrixd &X, const matrixd &P,
const vector<int> &targets, double eta)
{
int nt = P.size();
// dL/dY = P - T (cross-entropy + softmax)
matrixd dL_dY = P;
for (int i = 0; i < nt; i++)
dL_dY[i][targets[i]] -= 1.0;
// optional but recommended: normalize
for (int i = 0; i < nt; i++)
for (int j = 0; j < P[0].size(); j++)
dL_dY[i][j] /= nt;
// Gradient wrt weights
matrixd dL_dW = matmul(transpose(X), dL_dY);
// Gradient wrt input (back to decoder)
matrixd dL_dX = matmul(dL_dY, transpose(W));
//update weights after gradient computation
updateWeight(W, dL_dW, eta);
return dL_dX;
}
// ------------ Decoder Layer -------------------
DecoderLayer::DecoderLayer(int d_model, int nHeads, int d_ff)
: self_mha(d_model, nHeads),
cross_mha(d_model, nHeads),
ffn(d_model, d_ff),
norm1(d_model),
norm2(d_model),
norm3(d_model) {}
matrixd DecoderLayer::forward(const matrixd& input,
const matrixd& encoder_output)
{
X = input;
E = encoder_output;
self_mha.clearCache();
matrixd A1 = self_mha.computeAttention(X, X, X, true);
H1 = norm1.forward(X, A1);
cross_mha.clearCache();
matrixd A2 = cross_mha.computeAttention(H1, E, E, false);
H2 = norm2.forward(H1, A2);
matrixd A3 = ffn.FFoutput(H2);
H3 = norm3.forward(H2, A3);
return H3;
}
DecoderGrad DecoderLayer::backProp(const matrixd& dL_dY, double eta)
{
// =========================
// Step 1: FFN
// =========================
AddNormGrad g3 = norm3.backProp(H2, dL_dY, eta);
matrixd dL_dH2_res = g3.dL_dA;
matrixd dL_dFFN_in = g3.dL_dB;
matrixd dL_dH2_ffn = ffn.backProp(H2, dL_dFFN_in, eta);
matrixd dL_dH2 = addMat(dL_dH2_res, dL_dH2_ffn);
// =========================
// Step 2: Cross Attention
// =========================
AddNormGrad g2 = norm2.backProp(H1, dL_dH2, eta);
matrixd dL_dH1_res = g2.dL_dA;
matrixd dL_dCross = g2.dL_dB;
MHA_Gradient g_cross =
cross_mha.backProp(H1, E, E, dL_dCross, eta, false);
matrixd dL_dEnc = addMat(g_cross.dL_dK, g_cross.dL_dV); // encoder gradients
matrixd dL_dH1 = addMat(dL_dH1_res, g_cross.dL_dQ); // decoder path
// =========================
// Step 3: Self Attention
// =========================
AddNormGrad g1 = norm1.backProp(X, dL_dH1, eta);
matrixd dL_dX_res = g1.dL_dA;
matrixd dL_dSelf = g1.dL_dB;
MHA_Gradient g_self =
self_mha.backProp(X, X, X, dL_dSelf, eta, true);
matrixd dL_dSelf_mha = addMat(g_self.dL_dQ,
addMat(g_self.dL_dK, g_self.dL_dV));
matrixd dL_dX = addMat(dL_dX_res, dL_dSelf_mha);
return {dL_dX, dL_dEnc};
}
// ------------ Transformer (Encoder-Decoder) -------------------
MiniTrans::MiniTrans(int vocab_size_, int seq_len_,
int dModel_, int nHeads,
int d_ff, int nLayers)
: embed(vocab_size_, dModel_),
pe(seq_len_, dModel_),
output(dModel_, vocab_size_)
{
vocab_size = vocab_size_;
seq_len = seq_len_;
dModel = dModel_;
for (int i = 0; i < nLayers; i++) {
EncoderLayer e = EncoderLayer(dModel, nHeads, d_ff);
eLayers.push_back( e );
DecoderLayer d = DecoderLayer(dModel, nHeads, d_ff);
dLayers.push_back( d );
}
}
matrixd MiniTrans::forward(const vector<int> &source_tokens,
const vector<int> &target_in)
{
// =========================
// Encoder
// =========================
matrixd src_embed = embed.embed(source_tokens);
matrixd src_pe = pe.addPE(src_embed);
matrixd E = src_pe; // E will be final output of encoder
for (int i = 0; i < eLayers.size(); i++)
E = eLayers[i].forward(E);
// =========================
// Decoder
// =========================
matrixd tgt_embed = embed.embed(target_in);
matrixd tgt_pe = pe.addPE(tgt_embed);
matrixd dec = tgt_pe;
for (int i = 0; i < dLayers.size(); i++)
dec = dLayers[i].forward(dec, E);
// cache final decoder output (IMPORTANT for backward)
dec_out = dec;
// =========================
// Output layer
// =========================
matrixd P = output.forward(dec_out);
return P;
}
double MiniTrans::trainStep(const vector<int> &source,
const vector<int> &target_in,
const vector<int> &target_out,
double eta)
{
// =========================
// Step 1: Forward
// =========================
matrixd P = forward(source, target_in);
double loss = crossEntropy(P, target_out);
// =========================
// Step 2: Output backward
// =========================
matrixd dL_dX = output.backward(dec_out, P, target_out, eta);
// =========================
// Step 3: Decoder backward
// =========================
matrixd dL_dE; // accumulate gradients to encoder
bool first = true;
// accumulate encoder gradients dL_dE
for (int i = dLayers.size() - 1; i >= 0; i--) {
DecoderGrad g = dLayers[i].backProp(dL_dX, eta);
dL_dX = g.dL_dX;
if (first) {
dL_dE = g.dL_dE;
first = false;
} else {
dL_dE = addMat(dL_dE, g.dL_dE);
}
}
// =========================
// Step 4: Encoder backward
// =========================
for (int i = eLayers.size() - 1; i >= 0; i--)
dL_dE = eLayers[i].backProp(dL_dE, eta);
// =========================
// Step 5: Embedding update, optional
// =========================
embed.backProp(source, dL_dE, eta); // encoder side
embed.backProp(target_in, dL_dX, eta); // decoder side
return loss;
}
vector<int> MiniTrans::generate(const vector<int> &source, int max_len,
int start_token, int end_token)
{
// =========================
// Pass source through encoder
// =========================
matrixd src_embed = embed.embed(source);
matrixd src_pe = pe.addPE(src_embed);
matrixd E = src_pe;
for (int i = 0; i < eLayers.size(); i++)
E = eLayers[i].forward(E);
// =========================
// Initialize sequence
// =========================
vector<int> generated;
generated.push_back(start_token);
// =========================
// Autoregressive loop
// =========================
for (int step = 0; step < max_len; step++)
{
// embed current sequence
matrixd target_embed = embed.embed(generated);
matrixd target_pe = pe.addPE(target_embed);
matrixd dec = target_pe;
// pass through decoder
for (int i = 0; i < dLayers.size(); i++)
dec = dLayers[i].forward(dec, E);
matrixd P = output.forward(dec);
vector<double> last = P.back(); //last row of matrix P
int best_token = max_element(last.begin(), last.end()) - last.begin();
generated.push_back(best_token);
if (best_token == end_token)
break;
}
return generated;
}
|