Backpropagation of an AI Transformer in C/C++
Materials available at: http://forejune.co/cuda/
Transformer Layers
![]()
![]()
Forward Pass of a Decoder
Inputs:
Masked Self-Attention:
Cross Attention:
Feed-forward Network:
|
|
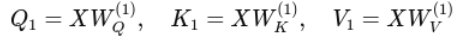
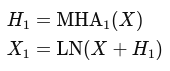
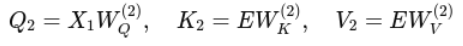
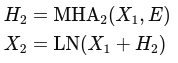
Materials available at: http://forejune.co/cuda/
Transformer Layers
![]()
![]()
Forward Pass of a Decoder
Inputs:
Masked Self-Attention:
Cross Attention:
Feed-forward Network:
|
|

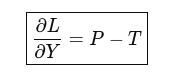
For each target token i 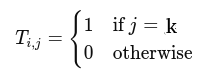
Don't need L to compute |
#include <vector>
#include <cmath>
#include <iostream>
#include "util.h"
using namespace std;
// Compute dL/dY
matrixd compute_dLdY(
const matrixd &Y, // logits (nt x nv)
const vector<int>& target // size nt (each in [0, nv-1])
)
{
int nt = Y.size();
int nv = Y[0].size();
matrixd T; // nt x nv
T.assign(nt, vector<double>(nv, 0.0));
matrixd dLdY = T; // same dimensions
for (int i = 0; i < nt; i++)
{
// Compute softmax probabilities
vector<double> P = softmax(Y[i]);
// Build one-hot target
int k = target[i];
T[i][k] = 1.0;
// Compute gradient: dL/dY = P - T
for (int j = 0; j < nv; j++)
{
dLdY[i][j] = P[j] - T[i][j];
}
/* Alternative code:
// Start with P
for (int j = 0; j < nv; j++)
dLdY[i][j] = P[j];
// Subtract 1 at correct class
dLdY[i][target[i]] -= 1.0;*/
}
return dLdY;
}
int main()
{
// Example: nt = 2 tokens, nv = 4 vocabulary
matrixd Y = {
{1.0, 2.0, 0.5, 0.5},
{0.2, 0.1, 3.0, 0.3}
};
int nt = Y.size();
int nv = Y[0].size();
vector<int> target = {1, 2}; // correct indices
matrixd dLdY = compute_dLdY(Y, target);
// Print results
cout << "dL/dY:\n";
for (int i = 0; i < nt; i++){
for (int j = 0; j < nv; j++)
cout << dLdY[i][j] << " ";
cout << endl;
}
return 0;
}
|
Weights or Quantities to be Updated:
The Backward Pass:
Final LayerNorm (Output):
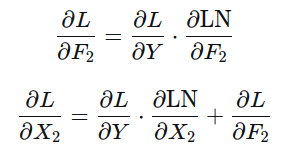
Feed-Forward Network:

|
Simplified
Relu activation function 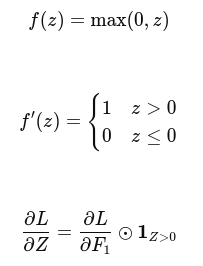
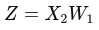
Z1 = Z = X2W1 |
Cross Multi-Head Attention:
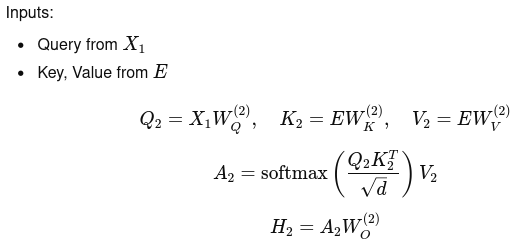

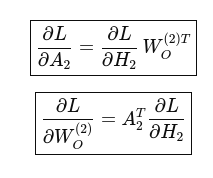

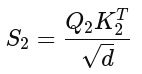
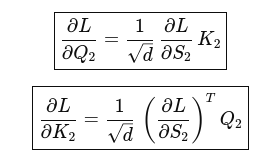

Masked Attention:

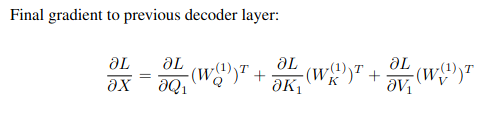
nt = number of tokens in target sequence ns = number of tokens in source sequence dmodel = model dimension nv = vocabulary size Decoder input X : nt x dmodel Decoder output Y : nt x nv Encoder output E : ns x dmodel Linear weights W : dmodel x nv Logits Z = X x W : nt x nv Probabilities P : nt x nv Target matrix T : nt x nv Loss L : a scalar γ, β : 1 x dmodel Gradient ∂L/∂β : 1 x dmodel Gradient Loss wrt output ∂L/∂Y : nt x nv Gradient Loss wrt weights ∂L/∂W : dmodel x nv Gradient Loss wrt input ∂L/∂X : nt x dmodel

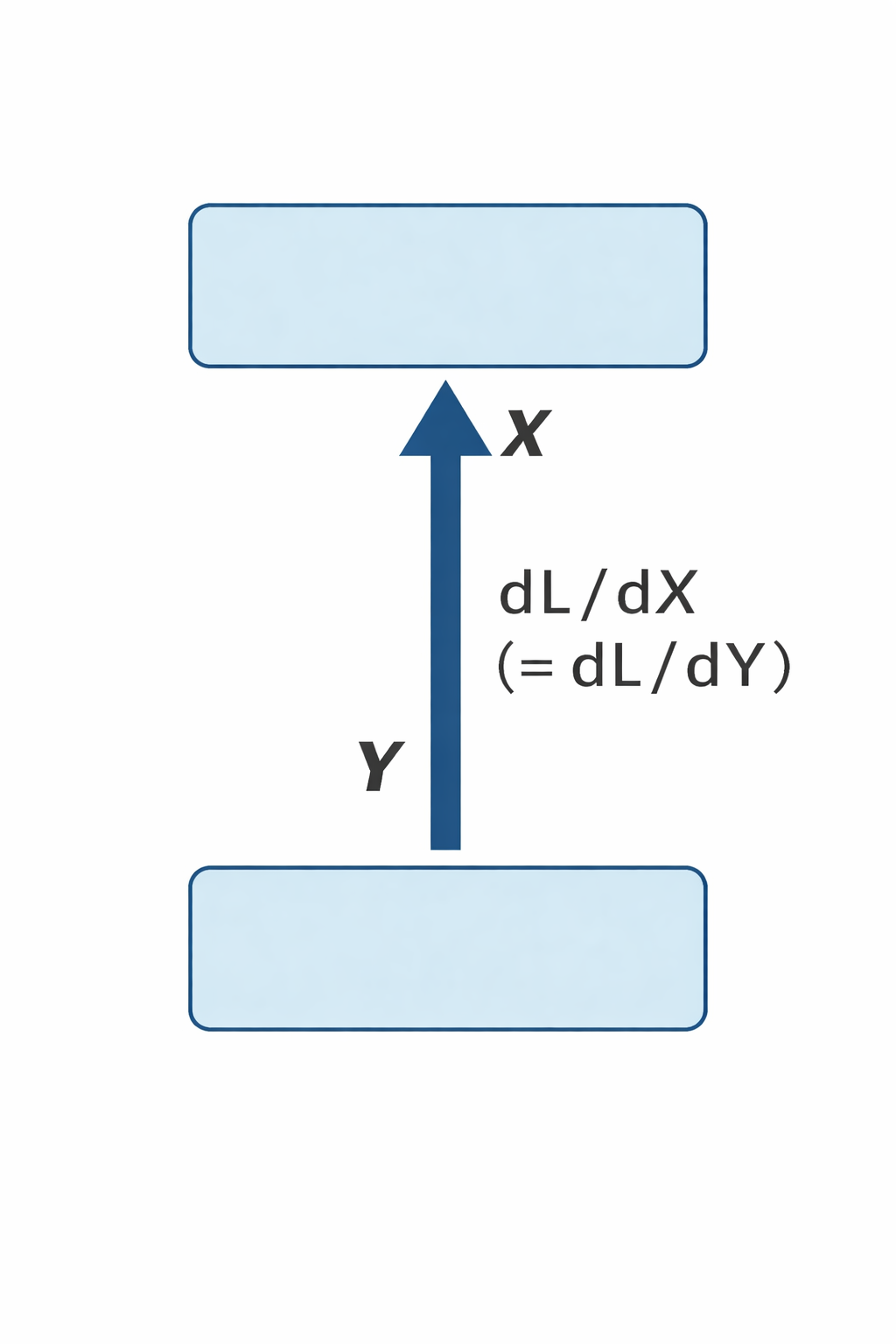
Backprop
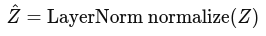 |
(~ x'ij above) |
Parameter Gradients: 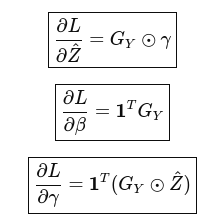
Backprop to input: 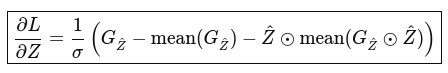
|
typedef vector<vector<double>> matrixd;
class AddnNorm
{
private:
vector<double> gamma; // size dModel
vector<double> beta; // size dModel
matrixd Zhat; // normalized values (nt x d)
vector<double> mean; // per row (nt)
vector<double> var; // per row (nt)
double eps; // small value
public:
// constructor
AddnNorm(int dModel)
{
gamma.assign(dModel, 1.0);
beta.assign(dModel, 0.0),
eps = 1e-5;
}
// Assume forward already filled: Zhat, mean, var
matrixd backProp(const matrixd &X,
const matrixd &dL_dY,
double eta)
{
int nt = X.size();
int m = X[0].size();
matrixd dL_dZ(nt, vector<double>(m, 0.0));
vector<double> dL_dGamma(m, 0.0);//gradient wrt gamma
vector<double> dL_dBeta(m, 0.0); //gradient wrt beta
// 1. Compute dL_dGamma and dL_dBeta for each token
for (int i = 0; i < nt; i++)
{
for (int j = 0; j < m; j++)
{
dL_dBeta[j] += dL_dY[i][j];
dL_dGamma[j] += dL_dY[i][j] * Zhat[i][j];
}
}
// 2. Update parameters
for (int j = 0; j < m; j++)
{
gamma[j] -= eta * dL_dGamma[j];
beta[j] -= eta * dL_dBeta[j];
}
// 3. Backprop through LayerNorm (row-wise)
for (int i = 0; i < nt; i++)
{
double inv_sigma = 1.0 / sqrt(var[i] + eps);
// Step A: compute intermediate values
vector<double> dL_dZhat(m);
for (int j = 0; j < m; j++)
{
dL_dZhat[j] = dL_dY[i][j] * gamma[j];
}
double sum_dL_dZhat = 0.0;
double sum_dL_dZhat_zhat = 0.0;
for (int j = 0; j < m; j++)
{
sum_dL_dZhat += dL_dZhat[j];
sum_dL_dZhat_zhat += dL_dZhat[j] * Zhat[i][j];
}
// Final gradient
for (int j = 0; j < m; j++)
{
dL_dZ[i][j] =
inv_sigma *
(dL_dZhat[j]
- sum_dL_dZhat / m
- Zhat[i][j] * sum_dL_dZhat_zhat / m);
}
}
return dL_dZ;
}
};
|
Feedforward Network:
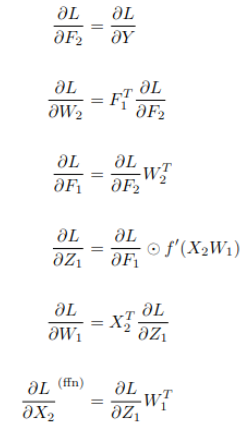
|
class FeedForward
{
private:
matrixd W1, W2;
int dModel, d_ff;
// cache
matrixd F1; // after activation function ReLU
matrixd Z; // before ReLU (needed for derivative)
public:
FeedForward(int dModel_, int d_ff_)
{
........
}
// ------------------------------
// Forward (for cache)
// ------------------------------
matrixd FFoutput(const matrixd &X)
{
Z = matmul(X, W1); // pre-activation
F1 = f(Z); // F1 = f(XW1)
matrixd F2 = matmul(F1, W2); // F2 = F1 W2
return F2;
}
// ------------------------------
// Backprop
// ------------------------------
matrixd backProp(const matrixd &X,
const matrixd &dL_dY, // dL/dF2
double eta)
{
// ---- W2 ----
matrixd dL_dF2 = dL_dY;
// dL/dW2 = F1^T * dL_dF2
matrixd F1T = transpose(F1);
matrixd dL_dW2 = matmul(F1T, dL_dF2);
// dL_dF1 = dL_dF2 * W2^T
matrixd W2T = transpose(W2);
matrixd dL_dF1 = matmul(dL_dF2, W2T);
// ---- find dL_dZ1 ----
matrixd fd_Z = f_deriv(Z);
int rows = dL_dF1.size();
int cols = dL_dF1[0].size();
matrixd dL_dZ1 = dL_dF1; // same dimension
for (int i = 0; i < rows; i++)
for (int j = 0; j < cols; j++)
dL_dZ1[i][j] = dL_dF1[i][j] * fd_Z[i][j];
// ---- W1 ----
// dL/dW1 = X^T * dL/dZ1
matrixd XT = transpose(X);
matrixd dL_dW1 = matmul(XT, dL_dZ1);
// dL/dX = dL/dZ1 * W1^T
matrixd W1T = transpose(W1);
matrixd dL_dX = matmul(dL_dZ1, W1T);
// ---- Update weights ----
for (int i = 0; i < W2.size(); i++)
for (int j = 0; j < W2[0].size(); j++)
W2[i][j] -= eta * dL_dW2[i][j];
for (int i = 0; i < W1.size(); i++)
for (int j = 0; j < W1[0].size(); j++)
W1[i][j] -= eta * dL_dW1[i][j];
return dL_dX; // This becomes the dL_dY of next stage
}
};
|
Multi-head Attention:
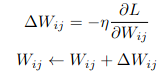
Softmax Derivative
row-sum(...) produces a column vector (nt x 1) then broadcast across columns Implementations use single-head math but full matrix |
void weightUpdate(matrixd &W, const matrixd &dL_dW, const double eta)
{
for (int i = 0; i < W.size(); i++)
for (int j = 0; j < W[0].size(); j++)
W[i][j] -= eta * dL_dW[i][j];
}
class MultiHeadAttention {
private:
int dModel, nHeads, d_k;
matrixd WQ, WK, WV, WO;
public:
MultiHeadAttention(int dModel, int nHeads)
: dModel(dModel), nHeads(nHeads)
{
d_k = dModel / nHeads;
....
}
// ----------- Forward -----------
matrixd computeAttention(const matrixd &X_Q,
const matrixd &X_K,
const matrixd &X_V,
bool mask) {
.....
return H;
}
// ----------- Backprop -----------
matrixd softmax_derivative(const matrixd &dL_dP,
const matrixd &P)
{
int nt = P.size(), ns = P[0].size();
matrixd dL_dS(nt, vector<double>(ns,0));
for (int i = 0; i < nt; i++)
{
double dot = 0.0;
// dot product of two row-vectors
for (int j = 0; j < ns; j++)
dot += P[i][j] * dL_dP[i][j];
// dot used by all columns of dL/dA
for (int j = 0; j < ns; j++)
dL_dS[i][j] = P[i][j] * (dL_dP[i][j] - dot);
}
return dL_dS;
}
matrixd backProp(const matrixd &X_Q,
const matrixd &X_K,
const matrixd &X_V,
const matrixd &dL_dH,
double eta,
bool mask) {
// ---- Forward recompute (needed for gradients) ----
matrixd Q = matmul(X_Q, WQ);
matrixd K = matmul(X_K, WK);
matrixd V = matmul(X_V, WV);
matrixd S = matmul(Q, transpose(K)); // nt x nt
double scale = 1.0 / sqrt((double)d_k);
int n, m;
scaleMat(S, scale);
matrixd P = softmax(S, mask);
matrixd A = matmul(P, V);
// ---- Backprop starts ----
// (1) dL/dA
matrixd dL_dA = matmul(dL_dH, transpose(WO));
// (2) dL/dWO
matrixd dL_dWO = matmul(transpose(A), dL_dH);
// (3) dL/dV
matrixd dL_dV = matmul(transpose(P), dL_dA);
// (4) dL/dP
matrixd dL_dP = matmul(dL_dA, transpose(V));
// (5) softmax backward --> dL/dS
matrixd dL_dS = softmax_derivative(dL_dP, P);
// (6) dL/dQ, dL/dK
matrixd dL_dQ = matmul(dL_dS, K);
scaleMat(dL_dQ, scale);
matrixd dL_dK = matmul(transpose(dL_dS), Q);
scaleMat(dL_dK, scale);
// (7) weight gradients
matrixd dL_dWQ = matmul(transpose(X_Q), dL_dQ);
matrixd dL_dWK = matmul(transpose(X_K), dL_dK);
matrixd dL_dWV = matmul(transpose(X_V), dL_dV);
// (8) input gradients
matrixd dL_dXQ = matmul(dL_dQ, transpose(WQ));
matrixd dL_dXK = matmul(dL_dK, transpose(WK));
matrixd dL_dXV = matmul(dL_dV, transpose(WV));
// (9) weights update
weightUpdate(WQ, dL_dWQ, eta);
weightUpdate(WK, dL_dWK, eta);
weightUpdate(WV, dL_dWV, eta);
weightUpdate(WO, dL_dWO, eta);
// Return gradient wrt X_Q (for chaining)
return dL_dXQ; // dL/dX1
}
};
|