A Hello-World Example of AI Transformer in C/C++ and CUDA
Materials available at: http://forejune.co/cuda/
Introduction
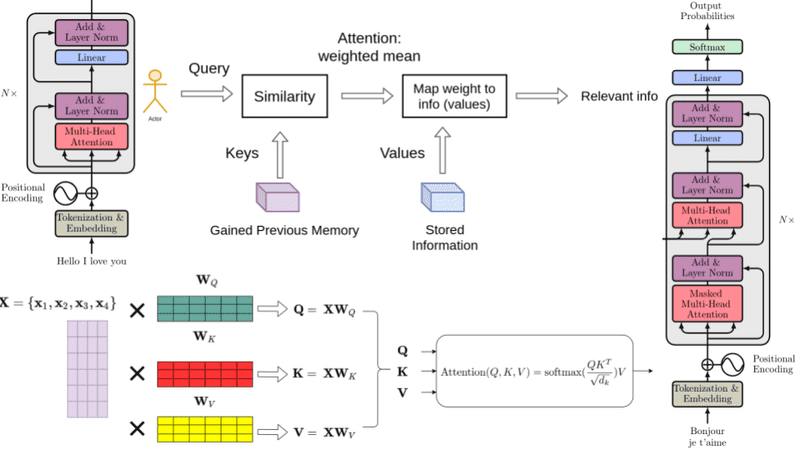
tokenization and embedding
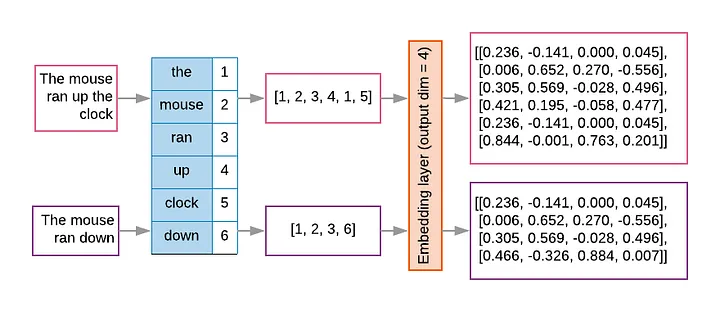
Example:
- A vocabulary has 10,000 tokens,
- Each embedding has 300 dimensions
- The embedding matrix is 10,000 x 300
Example:
A dog bit a man! is mundane news. A man bit a dog! is a sensational headline.
Transformer
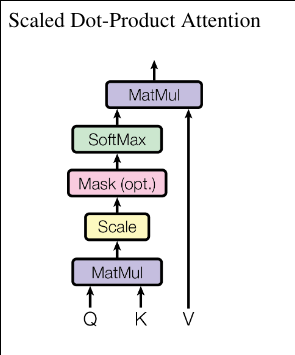
|

|
|
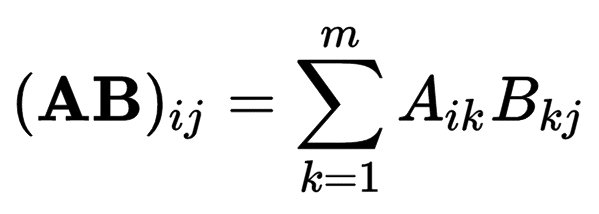
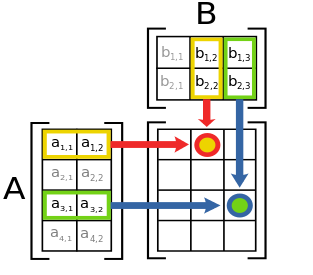
Each element of A x B is a dot product of a row vector of A and a column vector of B. Dimensions: A: 4 x 2 B: 2 x 3 ----------------- AxB: 4 x 3 |
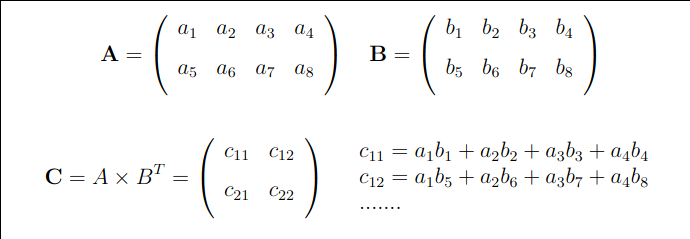
Note that the dimension of A X BT X A has the same dimension as A.
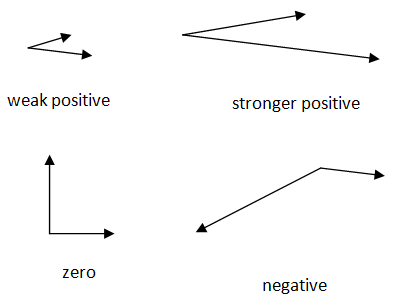
Consider two unit physical vectors. If they point in the same direction, dot-product = 1 If they are perpendicular to each other, dot-product = 0 If they point in opposite direction, dot-product = -1 dot-product ~ corelation or similarity between two vectors |
|

- Attention outputs are not used to update the Value (V) matrix
- The gradients derived from them during backpropagation are used to update V
- Note that weight matrices WQ,WK,WV are not the same as the corresponding matrices Q, K and V.
- Q, K and V are generated from the weight matrices, e.g.
Input Sequence (X) → X WV → V → Attention Output
(Provides gradient to update V)↑ ↑ ↑ Token
EmbeddingsLearned Weights
(Updated via gradients)Computed per input
(Not learned)
- Summary:
Matrix Origin When & How it's Updated Value Matrix (V) A projection of the input, used as the source for the weighted sum. Not updated during the forward pass. Value Weight Matrix (WV) The learned parameters that produce V from the input. Updated during the backward pass of training via gradient descent. Attention Output The weighted sum of V, Provides the gradient for updating WV.
C/C++ Implementation
CUDA Implementation
// transformer.cpp -- A hello-world example of transformer
// http://forejune.co/cuda/
#include <iostream>
#include <vector>
#include <cmath>
#include <random>
#include <algorithm>
using namespace std;
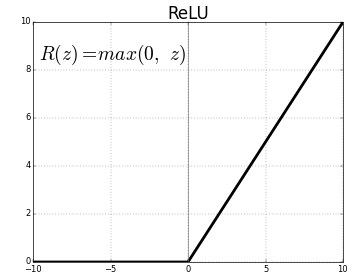
// Activation function: using ReLU (Rectified Linear Unit)
double f(double z)
{
return max(0.0, z);
}
// softmax activation function, 2D input vector
vector<vector<double>>
softmax(const vector<vector<double>>& input)
{
int n = input.size(), m = input[0].size();// n x m matrix
// 2D output vector n x m y[n][m]
vector< vector< double>> y(n, vector< double>(m));
for (int i = 0; i < n; i++) {
//maximum value of the row
double maxVal=*max_element(input[i].begin(),input[i].end());
double sum = 0;
// Subtract max for numerical stability
for (int j = 0; j < m; j++) {
y[i][j] = exp(input[i][j] - maxVal);
sum += y[i][j];
}
// Normalize
for (int j = 0; j < input[i].size(); j++)
y[i][j] /= sum;
}
return y;
}
// Matrix multiplication C = A X B A: nxm, B: mxr, C: nxr
vector<vector<double>> matmul(const vector<vector<double>>& A,
const vector<vector<double>>& B)
{
int n = A.size();
int m = A[0].size();
int r = B[0].size();
vector<vector<double>> C(n, vector<double>(r, 0));
for (int i = 0; i < n; i++)
for (int j = 0; j < r; j++)
for (int k = 0; k < m; k++)
C[i][j] += A[i][k] * B[k][j];
return C;
}
// Transpose matrix n x m, B = A^T : m x n
vector<vector<double>> transpose(const vector<vector<double>>& A)
{
int n = A.size(); //number of rows
int m = A[0].size(); //number of columns
vector<vector<double>> B(m, vector<double>(n)); // m x n
for (int i = 0; i < n; i++)
for (int j = 0; j < m; j++)
B[j][i] = A[i][j];
return B;
}
// Generating Random weights
void randomWeights(vector<vector<double>> &w )
{
int n = w.size();
int m = w[0].size();
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
w[i][j] = (rand() % 1000) /1000.0;
if ( rand() % 3 == 0 )
w[i][j] = -w[i][j];
}
}
}
// Hello-word transformer class
class HelloWorldTransformer
{
private:
int d; // Dimension of the model
int nTokens; // Sequence length
//Scaled dot-product attention, Q:Query, K:Key, V:Value
vector<vector<double>> scaled_attention(
const vector<vector<double>>& Q,
const vector<vector<double>>& K,
const vector<vector<double>>& V)
{
// Q X K^T
vector<vector<double>>QxKT = matmul(Q, transpose(K));
// Scale by sqrt(d_k)
double d = K[0].size();
double scale = sqrt(d);
for (int i = 0; i < QxKT.size(); i++)
for(int j = 0; j < QxKT[i].size(); j++)
QxKT[i][j] /= scale;
// Apply softmax
vector<vector<double>> attention_weights = softmax(QxKT);
// Multiply by V --> A x V
return matmul(attention_weights, V);
}
public:
HelloWorldTransformer(int sequence_len, int model_dim)
{
nTokens = sequence_len;
d = model_dim;
}
// Simple self-attention layer
vector<vector<double>> self_attention(const vector<vector<double>>& Q0,
const vector<vector<double>>& K0, const vector<vector<double>>& V0)
{
auto Q = Q0;
auto K = K0;
auto V = V0;
//return scaled_dot_product_attention(Q, K, V);
return scaled_attention(Q, K, V);
}
};
void printMatrix(const vector<vector<double>> &A)
{
for (const auto& row : A) {
for (double val : row) {
printf("%6.2f ", val);
}
cout << endl;
}
cout << endl;
}
int main()
{
srand(time (0));
// Configuration
int nTokens = 3; // Number of tokens (3 tokens)
int d = 4; // Embedding dimension
// Create transformer
HelloWorldTransformer transformer(nTokens, d);
// 3 tokens with 4 features (dimensions)
vector<vector<double>> X = {
{1, 0, 1, 0},
{0, 1, 0, 1},
{1, 1, 1, 1}
};
// weight matrices
vector<vector<double>> WQ(d, vector<double>(d));
vector<vector<double>> WK(d, vector<double>(d));
vector<vector<double>> WV(d, vector<double>(d));
randomWeights( WQ );
randomWeights( WK );
randomWeights( WV );
// Compute Q, K, V
auto Q = matmul(X, WQ); //Q = X x WQ: nTokens x d
auto K = matmul(X, WK); //Q = X x WK: nTokens x d
auto V = matmul(X, WV); //Q = X x WV: nTokens x d
cout << "Q, K, V embeddings:\n";
printMatrix( Q );
printMatrix( K );
printMatrix( V );
// Apply self-attention: Q, K, V
auto output = transformer.self_attention(Q, K, V);
cout << "Output after self-attention:\n";
printMatrix( output );
// Simple feed-forward network: FFN(x) = ReLU(W1*x)
// W1[d][d]: weights for generating linear sums from attention output
vector<vector<double>> W1 = {
{-1,-1,0,1},
{0,1,1,-1},
{1,0,1,0},
{1,1,1,0}
};
vector<vector<double>> z(nTokens, vector<double>(d));
auto FFout = z; // FFout has same dimensions as z
z = matmul(output, W1);
for (int i = 0; i < nTokens; i++)
for(int j = 0; j < d; j++)
FFout[i][j] = f(z[i][j]); //output of feed forward network
cout << "Transformer Block Output:\n";
printMatrix( FFout );
return 0;
}
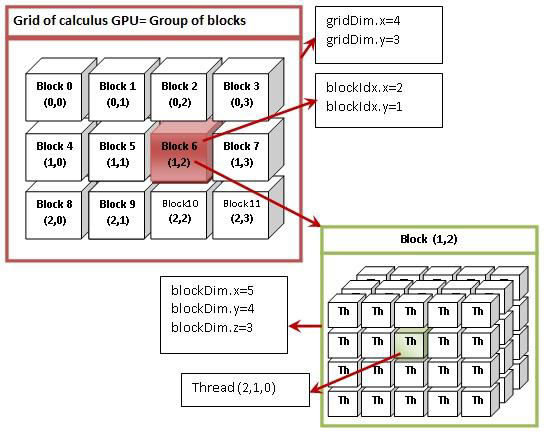
threadIdx.x = 2, threadIdx.y = 1, threadIdx.z = 0
// transformer.cu -- A hello-world example of transformer
// http://forejune.co/cuda/
#include <cstdio>
#include <cstdlib>
#include <cmath>
#include <cuda_runtime.h>
//Index for accessing nxm matrix element at position (i, j)
#define Idx(i,j,m) ((i)*(m)+(j))
/* ---------------- CUDA kernels ---------------- */
// C = A (nxm) x B (mxr)
__global__ void matmul(const double* A, const double* B, double* C,
int n, int m, int r)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < n && col < r) {
double sum = 0.0;
for (int k = 0; k < m; k++)
sum += A[Idx(row,k,m)] * B[Idx(k,col,r)];
C[Idx(row,col,r)] = sum;
}
}
__global__ void transpose(const double* A, double* B, int n, int m)
{
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < n && col < m)
B[Idx(col,row,n)] = A[Idx(row,col,m)];
}
// Row-wise softmax, n threads work in parallel
__global__ void softmax(double* A, int n, int m)
{
int row = blockIdx.x;
if (row < n) {
double maxv = A[Idx(row,0,m)];
for (int j = 1; j < m; j++)
maxv = fmax(maxv, A[Idx(row,j,m)]);
double sum = 0.0;
for (int j = 0; j < m; j++) {
A[Idx(row,j,m)] = exp(A[Idx(row,j,m)] - maxv);
sum += A[Idx(row,j,m)];
}
for (int j = 0; j < m; j++)
A[Idx(row,j,m)] /= sum;
}
}
// scaling
__global__ void scaling(double* A, const double sqrd, int n)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n)
A[i] /= sqrd;
}
/* ---------------- Host helpers ---------------- */
void randomWeights(double* W, int n, int m)
{
for (int i = 0; i < n*m; i++) {
W[i] = (rand() % 1000) / 1000.0;
if (rand() % 3 == 0) W[i] = -W[i];
}
}
void printMatrix(const double* A, int n, int m)
{
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++)
printf("%6.2f ", A[Idx(i,j,m)]);
printf("\n");
}
printf("\n");
}
/* ---------------- Main ---------------- */
int main()
{
// srand(time(0));
const int nTokens = 3;
const int d = 4;
// Host matrices
double X[nTokens*d] = {
1,0,1,0,
0,1,0,1,
1,1,1,1
};
double WQ[d*d], WK[d*d], WV[d*d], Q[nTokens*d], K[nTokens*d], KT[d*nTokens], V[nTokens*d];
randomWeights(WQ, d, d);
randomWeights(WK, d, d);
randomWeights(WV, d, d);
// Device memory
double *dX, *dWQ, *dWK, *dWV;
double *dQ, *dK, *dV;
double *dKT, *dScores, *dOut;
cudaMalloc(&dX, nTokens*d*sizeof(double));
cudaMalloc(&dWQ, d*d*sizeof(double));
cudaMalloc(&dWK, d*d*sizeof(double));
cudaMalloc(&dWV, d*d*sizeof(double));
cudaMalloc(&dQ, nTokens*d*sizeof(double));
cudaMalloc(&dK, nTokens*d*sizeof(double));
cudaMalloc(&dV, nTokens*d*sizeof(double));
cudaMalloc(&dKT, d*nTokens*sizeof(double));
cudaMalloc(&dScores, nTokens*nTokens*sizeof(double));
cudaMalloc(&dOut, nTokens*d*sizeof(double));
cudaMemcpy(dX, X, sizeof(X), cudaMemcpyHostToDevice);
cudaMemcpy(dWQ, WQ, sizeof(WQ), cudaMemcpyHostToDevice);
cudaMemcpy(dWK, WK, sizeof(WK), cudaMemcpyHostToDevice);
cudaMemcpy(dWV, WV, sizeof(WV), cudaMemcpyHostToDevice);
dim3 block(16,16); //block size: (16, 16)
dim3 gridSize(1, 1); //grid size: (1,1)
// Q = X WQ, K = X WK, V = X WV
matmul<<<gridSize,block>>>(dX,dWQ,dQ,nTokens,d,d);
matmul<<<gridSize,block>>>(dX,dWK,dK,nTokens,d,d);
matmul<<<gridSize,block>>>(dX,dWV,dV,nTokens,d,d);
cudaDeviceSynchronize();
cudaMemcpy(Q,dQ,sizeof(Q),cudaMemcpyDeviceToHost);
cudaMemcpy(K,dK,sizeof(K),cudaMemcpyDeviceToHost);
cudaMemcpy(V,dV,sizeof(V),cudaMemcpyDeviceToHost);
printf("Q, K, V embeddings:\n");
printMatrix(Q, nTokens, d);
printMatrix(K, nTokens, d);
printMatrix(V, nTokens, d);
// K^T transpose of K
transpose<<<gridSize, block>>>(dK, dKT, nTokens, d);
cudaDeviceSynchronize();
cudaMemcpy(KT,dKT,sizeof(KT),cudaMemcpyDeviceToHost);
// Scores = Q K^T
matmul<<<gridSize,block>>>(dQ,dKT,dScores,nTokens,d,nTokens);
// Scale
double scale = sqrt((double)d);
int total = nTokens*nTokens;
// one block has 256 threads
scaling<<<(total+255)/256,256>>>(dScores, scale, total);
cudaDeviceSynchronize();
// Softmax, nTokens blocks, 1 thread per block
softmax<<<nTokens,1>>>(dScores,nTokens,nTokens);
// Output = Scores V
matmul<<<gridSize,block>>>(dScores,dV,dOut,nTokens,nTokens,d);
// Copy back
double output[nTokens*d];
cudaMemcpy(output,dOut,sizeof(output),cudaMemcpyDeviceToHost);
printf("Output after self-attention:\n");
printMatrix(output,nTokens,d);
cudaFree(dX); cudaFree(dWQ); cudaFree(dWK); cudaFree(dWV);
cudaFree(dQ); cudaFree(dK); cudaFree(dV);
cudaFree(dKT); cudaFree(dScores); cudaFree(dOut);
return 0;
}