Using Softmax Function in Machine Learning
Materials available at: https://forejune.co/cuda/
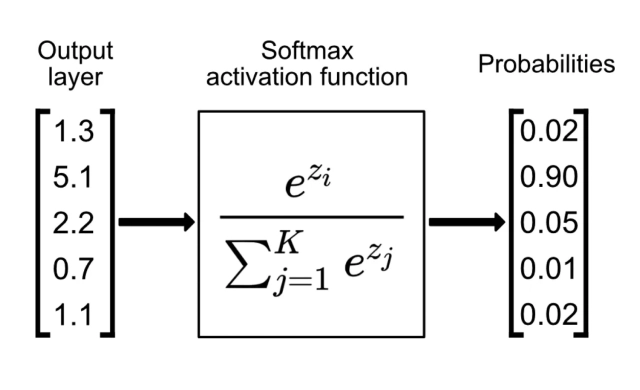
The Softmax Function
|
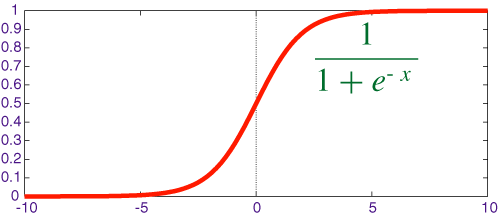
Sigmoid Function |
|
Sigmoid Function
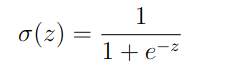 |
Softmax Function
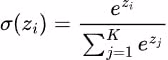
|
In neural networks, logits are the raw, unnormalized scores produced at a model's output layer before the activation function is applied.
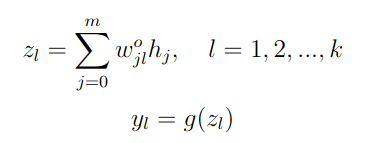
zl are logits g() is an activation function wo0l is the bias, and h0 = 1 |

|
|
|
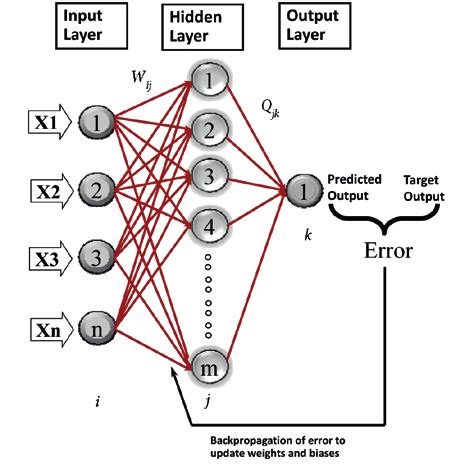
Full Adder MLP Using Sigmoid Function
Binary Full Adder
x1
x2
+ x3
-----------------
C S (carry, sum)
x3 x2 x1 | C S
---------|-----------
0 0 0 | 0 0
0 0 1 | 0 1
0 1 0 | 0 1
0 1 1 | 1 0
1 0 0 | 0 1
1 0 1 | 1 0
1 1 0 | 1 0
1 1 1 | 1 1
3 inputs, 2 outputs, i.e. n1 = 4, K = 2
use 4 hidden nodes, so m1 = 5
See https://forejune.co/cuda/ai/mlp/mlp.html
// fullAdder.cpp
// https://forejune.co/cuda
#include <iostream>
#include <iomanip>
#include <cmath>
using namespace std;
const int n1 = 4; //number of inputs and bias
const int m1 = 5; //number of hidden nodes and bias
const int K = 2; //number of outputs
const int numSamples = 8;
double inputs[numSamples][n1] =
{
1, 0, 0, 0, //x0=1, x1=0, x2=0, x3 = 0
1, 0, 0, 1,
1, 0, 1, 0,
1, 0, 1, 1,
1, 1, 0, 0,
1, 1, 0, 1,
1, 1, 1, 0, //x0=1, x1=1, x2=1, x3=0
1, 1, 1, 1 //x0=1, x1=1, x2=1, x2=1
};
double labels[numSamples][K] = {
0, 0,
0, 1,
0, 1,
1, 0,
0, 1,
1, 0,
1, 0,
1, 1}; //target outputs (labels)
double w[n1][m1] = {
0.97, 0.2, 0.7, 0.5, 0.65,
0.73, 0.1, 0.9, 0.3, 0.23,
0.37, 0.3, 0.8, 0.3, 0.19,
0.2, 0.7, 0.3, 0.6, 0.87}; //random weights (input to hidden)
double wo[m1][K] = {
0.76, 0.6, 0.1, 0.2, 0.7,
0.67, 0.45, 0.3, 0.15, 0.4}; //random weights (hidden to output)
// Simple MLP class
class MLP
{
private:
double a[m1]; //linear sum of products of inputs and weights
double h[m1]; //hidden nodes h[j] = g(a[j])
double y[K]; //predicted output
double z[K]; //linear sum of products of weights and hidden nodes (logits)
double eta; //learning rate
public:
MLP(double learning_rate)
{
eta = learning_rate;
h[0] = 1; //for bias
}
//Sigmoid activation function
double g(double x)
{
return 1.0 / (1.0 + exp(-x));
}
//Derivative of sigmoid function
double gd(double x)
{
double s = g(x);
return s * (1 - s);
}
//Forward propagation
double* forward(double x[])
{
//hidden layer activation
for (int j = 0; j < m1; j++) {
a[j] = 0;
for (int i = 0; i < n1; i++)
a[j] += w[i][j] * x[i];
if ( j > 0 )
h[j] = g( a[j] );
}
//output layer activation
for (int l = 0; l < K; l++){
z[l] = 0;
for(int j = 0; j < m1; j++)
z[l] += wo[j][l] * h[j];
y[l] = g( z[l] );
}
return y; //return output
}
//Backward propagation, yd is the desired output
void backward(double yd[], double x[])
{
double delta[m1];
double deltao[K];
for (int l = 0; l < K; l++) {
double e = yd[l] - y[l]; //output layer error
deltao[l] = e * gd(z[l]);
}
//Compute hidden layer error
for(int j = 0; j < m1; j++){
delta[j] = 0;
for(int l = 0; l < K; l++)
delta[j] += deltao[l] * wo[j][l] * gd(a[j]);
}
//Update weights (hidden to output)
for(int j = 0; j < m1; j++)
for(int l = 0; l < K; l++)
wo[j][l] += eta * deltao[l] * h[j];
//Update weights (input to hidden)
for(int i = 0; i < n1; i++)
for(int j = 0; j < m1; j++)
w[i][j] += eta * delta[j] * x[i];
}
void get_input_data(int k, double x[])
{
for(int i=0; i < n1; i++)
x[i]=inputs[k][i];
}
// Train the perceptron
// eta = learning rate
// epochs = number of times of training
// numSamples = number of different input sets (x_data)
// yd is target output
void train(int numSamples, int epochs)
{
double x[n1]; //inputs
double *yd = &labels[0][0];
for (int epoch = 0; epoch < epochs; epoch++){
for (int k = 0; k < numSamples; k++) {
get_input_data(k, x);
forward( x );
backward(yd+k*K, x);
}
}
}
void printWeights()
{
cout << "\nMLP input to hidden weights: ";
for(int i = 0; i < n1; i++){
cout << endl;
for(int j = 0; j < m1; j++)
printf("w[%d][%d]: %6.3f\t", i, j, w[i][j]);
}
cout << "\nMLP hidden to output weights:";
for(int i = 0; i < m1; i++) {
cout << endl;
for(int j = 0; j < K; j++)
printf("wo[%d][%d]: %6.3f\t", i, j, wo[i][j]);
}
}
~MLP()
{
}
};
int classifier( double x)
{
if ( x < 0.2 && x > -0.1)
return 0;
if ( x > 0.8 && x < 1.1)
return 1;
return -1;
}
int main()
{
MLP mlp(0.5);
mlp.train(8, 10000);
// Test the MLP
double *x;
x = &inputs[0][0];
cout << "Testing MLP:" << endl;
for (int i = 0; i < 8; i++) {
double *output = mlp.forward(x);
cout << fixed << setprecision(0) << " " << x[1] << " " <<
x[2] << " " << x[3] << " : " << classifier(output[0]) << " "
<< classifier (output[1]) << " (" << setprecision(2) << output[0]
<< " " << output[1]<<")" << endl;
x += 4;
}
mlp.printWeights();
cout << endl << "Hello, AI World!" << endl;
return 0;
}
|
Full Adder MLP Using Softmax Function
x3 x2 x1 | Class 0 1 2 3 ---------|----------------------- 0 0 0 | 0 1 0 0 0 0 0 1 | 1 0 1 0 0 0 1 0 | 1 0 1 0 0 0 1 1 | 2 0 0 1 0 1 0 0 | 1 0 1 0 0 1 0 1 | 2 0 0 1 0 1 1 0 | 2 0 0 1 0 1 1 1 | 3 0 0 0 1
const int n1 = 4; //number of inputs and bias
const int m1 = 7; //number of hidden nodes and bias
const int K = 4; //number of outputs
const int numSamples = 8;
double inputs[numSamples][n1] =
{
1, 0, 0, 0, //x0=1, x1=0, x2=0, x3 = 0
1, 0, 0, 1,
1, 0, 1, 0,
1, 0, 1, 1,
1, 1, 0, 0,
1, 1, 0, 1,
1, 1, 1, 0, //x0=1, x1=1, x2=1, x3=0
1, 1, 1, 1 //x0=1, x1=1, x2=1, x2=1
};
double labels[numSamples][K] = {
1, 0, 0, 0,
0, 1, 0, 0,
0, 1, 0, 0,
0, 0, 1, 0,
0, 1, 0, 0,
0, 0, 1, 0,
0, 0, 1, 0,
0, 0, 0, 1};
double w[n1][m1] = {
0.97, 0.2, 0.7, 0.5, 0.65,
0.73, 0.1, 0.9, 0.3, 0.23,
0.37, 0.3, 0.8, 0.3, 0.19,
0.2, 0.7, 0.3, 0.6, 0.87}; //random weights (input to hidden)
double wo[m1][K] = {
0.76, 0.6, 0.1, 0.2, 0.7,
0.67, 0.45, 0.3, 0.15, 0.4,
0.12, 0.87, 0.9, 0.6, 0.2,
0.8, 0.5, 0.44, 0.73, 0.52
}; //random weights (hidden to output)
class MLP
{
.....
//denominator of softmax
double sumExp()
{
double sum = 0;
for (int l = 0; l < K; l++)
sum += exp( z[l] );
return sum;
}
//Forward propagation
double* forward(double x[])
{
//hidden layer activation
for (int j = 0; j < m1; j++) {
a[j] = 0;
for (int i = 0; i < n1; i++)
a[j] += w[i][j] * x[i];
if ( j > 0 )
h[j] = g( a[j] );
}
//output layer activation
for (int l = 0; l < K; l++){
z[l] = 0;
for(int j = 0; j < m1; j++)
z[l] += wo[j][l] * h[j];
}
//softmax
double denom = sumExp();
for (int l = 0; l < K; l++)
y[l] = exp(z[l]) / denom;
return y; //return output
}
void printProbabilities( double *output )
{
for (int l = 0; l < K; l++)
printf("%4.2f, ", output[l] );
printf("\t");
}
int predict(double x[])
{
double *output = forward( x );
printProbabilities( output );
int label = 0;
double maxProb = output[0];
for (int l = 0; l < K; l++) {
if (output[l] > maxProb) {
maxProb = output[l];
label = l;
}
}
return label;
}
};
int main()
{
MLP mlp(0.5);
mlp.train(8, 10000);
// Test the MLP
double *x;
x = &inputs[0][0];
cout << "Testing MLP:" << endl;
for (int i = 0; i < 8; i++) {
int label = mlp.predict( x );
cout << fixed << setprecision(0) << " " << x[1] << " " <<
x[2] << " " << x[3] << " : " << label << " " << endl;
x += 4;
}
cout << endl << "Hello, AI World!" << endl;
return 0;
}
|
A simplified version of K-means clustering using MLP
// softmaxDemo.cpp
// https://forejune.co/cuda
#include <iostream>
#include <iomanip>
#include <cmath>
using namespace std;
const int n1 = 3; //number of inputs and bias
const int m1 = 7; //number of hidden nodes and bias
const int K = 3; //3 classes, number of outputs
const int numSamples = 6;
double w1[n1][m1];
// inputs could be normalized (x, y) coordinates
double inputs[numSamples][n1] =
{
1, 0.1, 0.2,
1, 0.8, 0.9,
1, 0.3, 0.6,
1, 0.5, 0.4,
1, 0.2, 0.3,
1, 0.7, 0.8};
double labels[numSamples][K] = {
1, 0, 0, //class 0 (cluster 0)
0, 0, 1, //class 2
0, 1, 0, //class 1
0, 1, 0, //class 1
1, 0, 0, //class 0
0, 0, 1}; //class 2
double w[n1][m1] = {
0.97, 0.2, 0.7, 0.5, 0.65, 0.1, 0.9,
0.73, 0.1, 0.9, 0.3, 0.23, 0.2, 0.8,
0.2, 0.7, 0.3, 0.6, 0.87, 0.4, 0.7}; //random weights (input to hidden)
double wo[m1][K] = {
0.76, 0.6, 0.1,
0.2, 0.7, 0.67,
0.45, 0.3, 0.15,
0.4, 0.8, 0.5,
0.44, 0.73, 0.52
}; //random weights (hidden to output)
// Simple MLP class
class MLP
{
private:
double a[m1]; //linear sum of products of inputs and weights
double h[m1]; //hidden nodes h[j] = g(a[j])
double y[K]; //predicted output
double z[K]; //linear sum of products of weights and hidden nodes
double eta; //learning rate
public:
MLP(double learning_rate)
{
eta = learning_rate;
h[0] = 1; //for bias
}
//Sigmoid activation function
double g(double x)
{
return 1.0 / (1.0 + exp(-x));
}
//Derivative of sigmoid function
double gd(double x)
{
double s = g(x);
return s * (1 - s);
}
//denominator of softmax
double sumExp()
{
double sum = 0;
for (int l = 0; l < K; l++)
sum += exp( z[l] );
return sum;
}
//Forward propagation
double* forward(double x[])
{
//hidden layer activation
for (int j = 0; j < m1; j++) {
a[j] = 0;
for (int i = 0; i < n1; i++)
a[j] += w[i][j] * x[i];
if ( j > 0 )
h[j] = g( a[j] );
}
//output layer activation
for (int l = 0; l < K; l++){
z[l] = 0;
for(int j = 0; j < m1; j++)
z[l] += wo[j][l] * h[j]; //logits
}
//softmax
double denom = sumExp();
for (int l = 0; l < K; l++)
y[l] = exp(z[l]) / denom;
return y; //return output
}
//Backward propagation, yd is the desired output
void backward(double yd[], double x[])
{
double delta[m1];
double deltao[K];
for (int l = 0; l < K; l++) {
double e = yd[l] - y[l]; //output layer error
deltao[l] = e * gd(z[l]);
}
for(int j = 0; j < m1; j++){
delta[j] = 0;
for(int l = 0; l < K; l++)
delta[j] += deltao[l] * wo[j][l] * gd(a[j]);
}
//Update weights (hidden to output)
for(int j = 0; j < m1; j++)
for(int l = 0; l < K; l++)
wo[j][l] += eta * deltao[l] * h[j];
//Update weights (input to hidden)
for(int i = 0; i < n1; i++)
for(int j = 0; j < m1; j++)
w[i][j] += eta * delta[j] * x[i];
}
void get_input_data(int k, double x[])
{
for(int i=0; i < n1; i++)
x[i]=inputs[k][i];
}
// Train the perceptron
// eta = learning rate
// epochs = number of times of training
// numSamples = number of different input sets (x_data)
// yd is target output
void train(int numSamples, int epochs)
{
double x[n1]; //inputs
double *yd = &labels[0][0];
for (int epoch = 0; epoch < epochs; epoch++){
for (int k = 0; k < numSamples; k++) {
get_input_data(k, x);
forward( x );
backward(yd+k*K, x);
}
}
}
void printProbabilities( double *output )
{
for (int l = 0; l < K; l++)
printf("%4.2f, ", output[l] );
printf("\t");
}
int predict(double x[])
{
double *output = forward( x );
printProbabilities( output );
int label = 0;
double maxProb = output[0];
for (int l = 0; l < K; l++) {
if (output[l] > maxProb) {
maxProb = output[l];
label = l;
}
}
return label;
}
void printWeights()
{
cout << "\nMLP input to hidden weights: ";
for(int i = 0; i < n1; i++){
cout << endl;
for(int j = 0; j < m1; j++)
printf("w[%d][%d]: %5.3f\t", i, j, w[i][j]);
}
cout << "\nMLP hidden to output weights:";
for(int i = 0; i < m1; i++) {
cout << endl;
for(int j = 0; j < K; j++)
printf("wo[%d][%d]: %5.3f\t", i, j, wo[i][j]);
}
}
~MLP()
{
}
};
int main()
{
MLP mlp(0.5);
mlp.train(6, 10000);
// Test the MLP
double *x;
const int ntest = 9;
double test_inputs[ntest][n1] =
{
1, 0.1, 0.2,
1, 0.8, 0.9,
1, 0.3, 0.6,
1, 0.5, 0.4,
1, 0.2, 0.3,
1, 0.7, 0.8,
1, 0.1, 0.1,
1, 0.5, 0.5,
1, 0.9, 0.9
};
x = &test_inputs[0][0];
cout << "Testing MLP:" << endl;
for (int i = 0; i < ntest; i++) {
int label = mlp.predict( x );
cout << fixed << setprecision(2) << " " << x[1] << " " << x[2]
<< " : " "Class " << label << " " << endl;
x += n1;
}
return 0;
}
|
Outputs:Testing MLP: 1.00, 0.00, 0.00, 0.10 0.20 : Class 0 0.00, 0.00, 1.00, 0.80 0.90 : Class 2 0.00, 0.99, 0.00, 0.30 0.60 : Class 1 0.00, 0.99, 0.00, 0.50 0.40 : Class 1 0.99, 0.01, 0.00, 0.20 0.30 : Class 0 0.00, 0.00, 1.00, 0.70 0.80 : Class 2 1.00, 0.00, 0.00, 0.10 0.10 : Class 0 0.00, 0.99, 0.01, 0.50 0.50 : Class 1 0.00, 0.00, 1.00, 0.90 0.90 : Class 2