| |
// tictactoe.cpp
// reinforcement learning with Q-Learning
// https://forejune.co/cuda/
#include <iostream>
#include <ctime>
using namespace std;
//set up
const double alpha = 0.1;
const double gamma = 0.9;
const double epsilon = 0.1;
//number of states Nstates = 3^9 = 19683
#define Nstates 19683
enum Player {EMPTY=0, X, O};
Player board[9];
double Q[Nstates][9]; //Q[state][action]
/*
* A state is a configuration of the board
* Totally 3^9 different states
* An action represents the location of the board where one
* wants to mark X or O
*/
void resetBoard()
{
for (int i = 0; i < 9; i++)
board[i] = EMPTY;
}
void printBoard()
{
char symbols[3] = {' ', 'X', 'O'};
for (int i = 0; i < 3; ++i) {
for (int j = 0; j < 3; ++j) {
Player p = board[3*i+j];
cout << symbols[p];
if (j < 2) cout << " | ";
}
cout << endl;
if (i < 2) cout << "---------" << endl;
}
}
void initialization()
{
resetBoard();
for (int i = 0; i < Nstates; i++)
for (int j = 0; j < 9; j++)
Q[i][j] = 0.0;
}
//return state of board, a state is specified by an integer
int getState()
{
int s = 0, m =1;
for(int i = 0; i < 9; i++){
s += m * board[i];
m = m * 3;
}
return s;
}
void updateQtable(int state, int action, double reward, int nextState)
{
double maxQnext = 0.0; //maximum Q value of the next state
double q;
for (int j = 0; j < 9; j++){
q = Q[nextState][j];
if (q > maxQnext) maxQnext = q;
}
Q[state][action] += alpha * (reward + gamma * maxQnext - Q[state][action]);
}
//choose best location (action) to mark X or O
int chooseAction(int s, bool explore)
{
int i;
if ((double)rand() / RAND_MAX < epsilon && explore == true) {
// Exploration
int n = 0;
int moves[9];
for (i = 0; i < 9; i++)
if (board[i] == EMPTY) moves[n++] = i;
if (n == 0) return -1; //no more space
//choose randomly one of the available space randomly
i = rand() % n;
return moves[i];
} else {
// Exploitation
// Choose the action with maximum quality
int bestMove = -1;
double max_q = -1000;
for (i = 0; i < 9; i++) {
if (board[i] == EMPTY) {
double q = Q[s][i];
if (q > max_q) {
max_q = q;
bestMove = i;
}
}
}
return bestMove;
}
}
bool isWinning(Player player)
{
const int w[8][3] = { //winning positions
{0,1,2},{3,4,5},{6,7,8}, //rows | 0 | 1 | 2 |
{0,3,6},{1,4,7},{2,5,8}, //columns | 3 | 4 | 5 |
{0,4,8},{2,4,6} //diagonals| 6 | 7 | 8 |
};
for (int i = 0; i < 8; i++){
if (board[w[i][0]]==player && board[w[i][1]]==player
&& board[w[i][2]]==player)
return true;
}
return false;
}
bool isDraw()
{
//no more empty space
for (int i = 0; i < 9; i++)
if (board[i] == EMPTY)
return false;
return true; //no more empty space
}
// Train AI agent vs itself
void train( int episodes)
{
bool win, draw;
int state, action, nextState;
//For recording states and actions of players X and O as they play
struct StateActions {
int state[9];
int action[9];
int n = 0;
void put(int s, int a){
state[n] = s;
action[n] = a;
n++;
}
};
initialization(); //set Q table values to 0
for (int ep = 0; ep < episodes; ep++) {
resetBoard(); //reset board
Player currentPlayer = X;
StateActions Xsa, Osa;
while (true) {
state = getState(); //current state
action = chooseAction(state, true);
if (action < 0) break;
board[action] = currentPlayer; //putting X or O on board
nextState = getState(); // lead to a new state
win = isWinning(currentPlayer);
draw = isDraw();
if (currentPlayer == X) Xsa.put(state, action);
else Osa.put(state, action);
if (win || draw) {
//rewards for player X and O
double rX = (win && currentPlayer == X) ? 1 : (win ? -1 : 0);
double rO = -rX;
for (int i = 0; i < Xsa.n; i++)
updateQtable(Xsa.state[i], Xsa.action[i], rX, nextState);
for (int i = 0; i < Osa.n; i++)
updateQtable(Osa.state[i], Osa.action[i], rO, nextState);
break;
}
//switch current player
currentPlayer = (currentPlayer == X ? O : X);
}
}
cout << "Training completed!" << endl;
}
// Let human play against trained AI
void play()
{
resetBoard();
Player currentPlayer = X;
cout << "You are 'O'. AI is 'X'!" << endl;
while (true) {
if (currentPlayer == O) {
int move;
cout << "Your move (0-8): ";
cin >> move;
if (move < 0 || move > 8 || board[move] != EMPTY) {
cout << "Invalid move. Try again!" << endl;
continue;
}
board[move] = O;
} else {
int state = getState(); //get state of current board
int aiMove = chooseAction(state, false);
cout << "AI moves at " << aiMove << endl;
board[aiMove] = X;
}
printBoard();
if (isWinning(currentPlayer)) {
cout << (currentPlayer == X ? "AI wins!" : "You win!") << endl;
break;
} else if ( isDraw() ) {
cout << "It's a draw!" << endl;
break;
}
currentPlayer = (currentPlayer == X ? O : X);
}
}
int main()
{
srand(time(0));
train( 50000 );
play();
return 0;
}
|

|
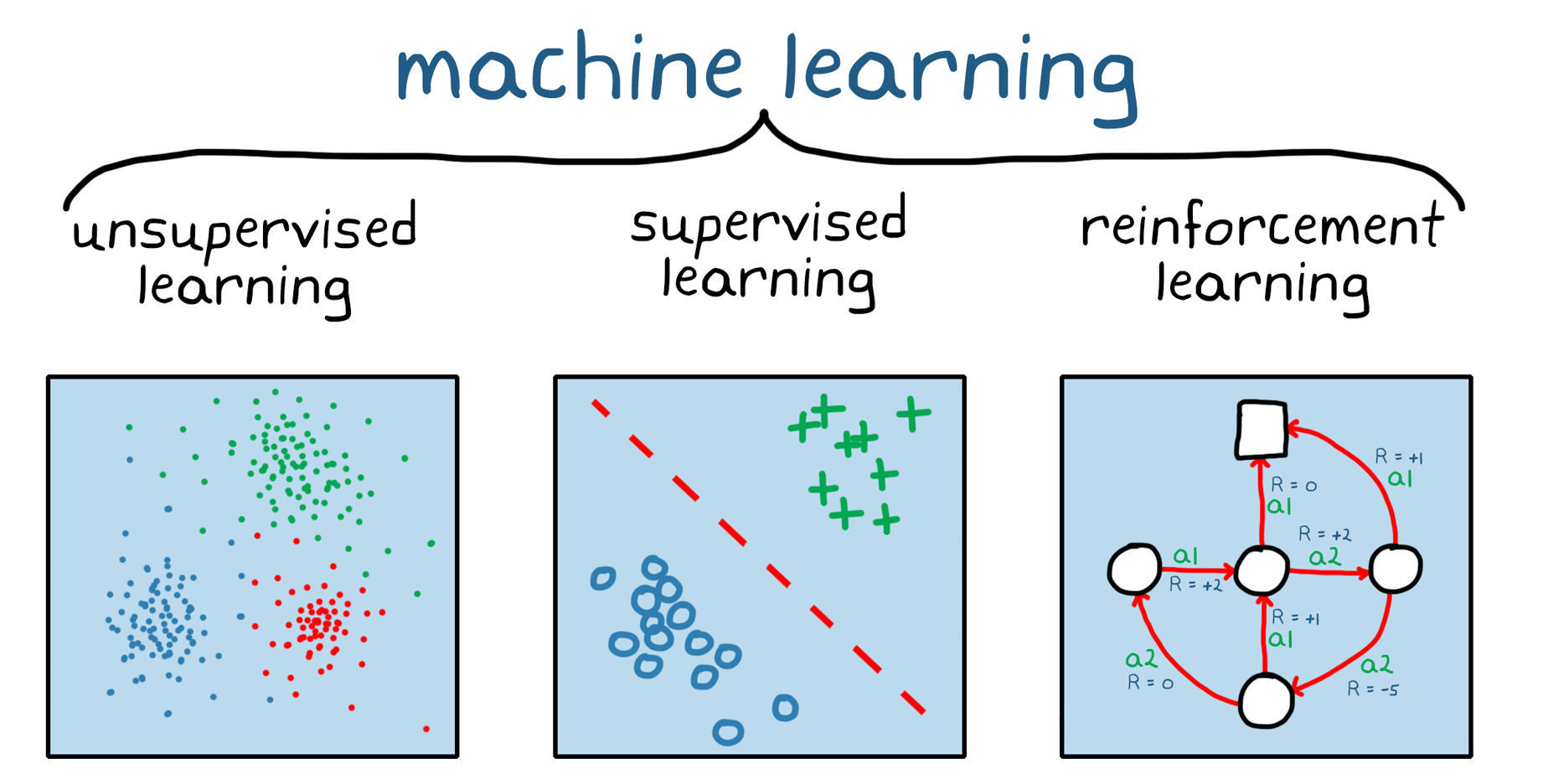
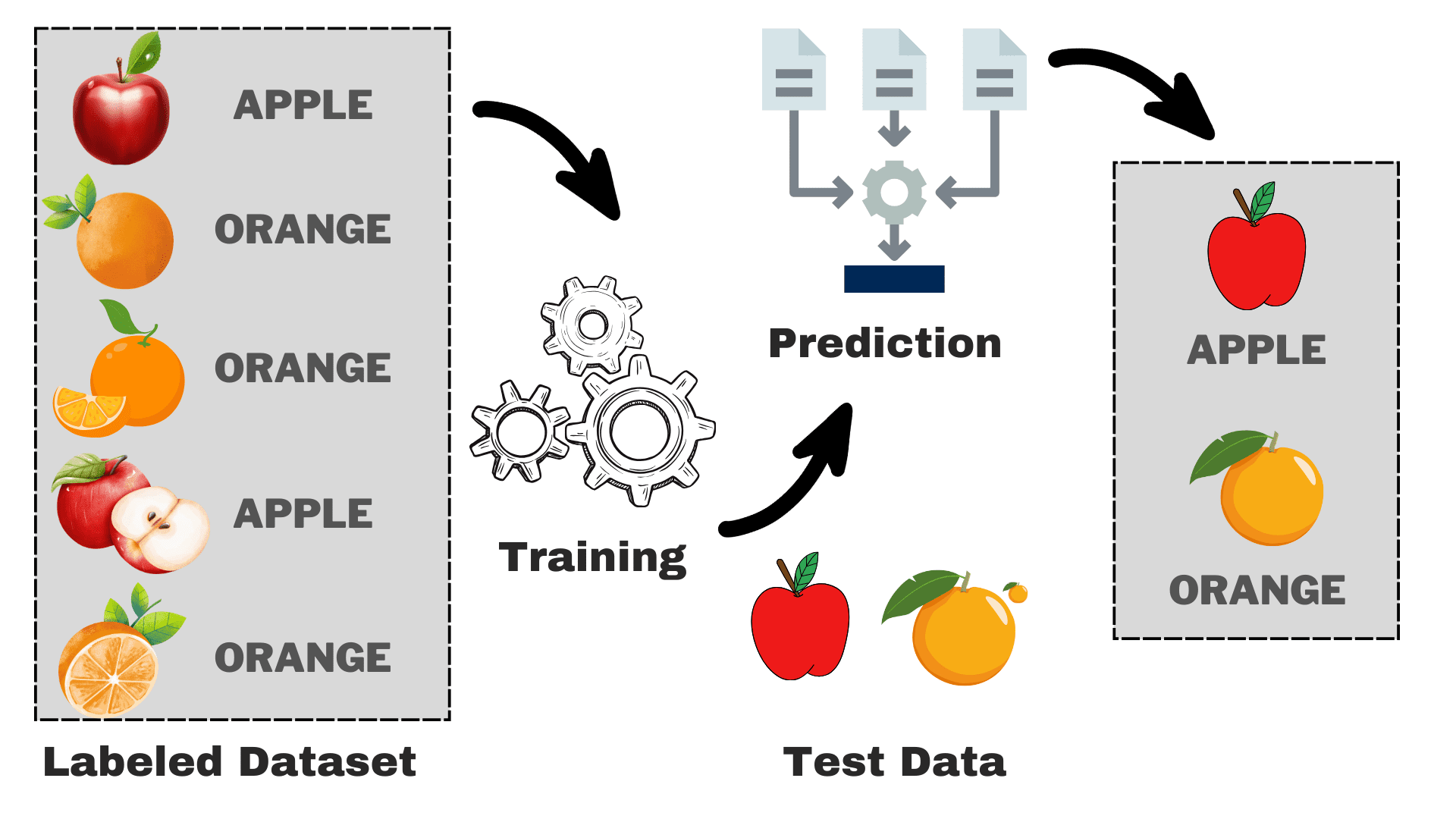

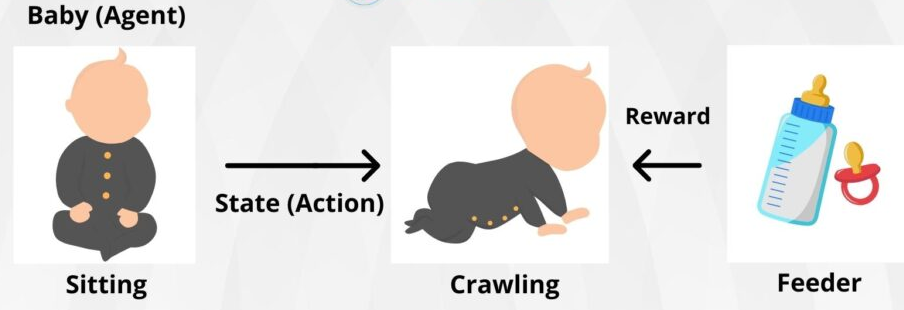



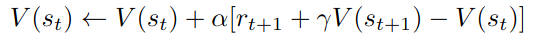
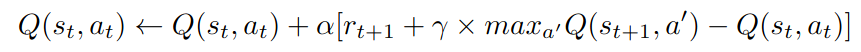


 Represent a state by an integer:
Represent a state by an integer: