Implementing a Neural Network with Many Hidden Layers in C/C++
Materials available at: https://forejune.co/cuda/
Reviews
Multi-Layer Perceptron (MLP)
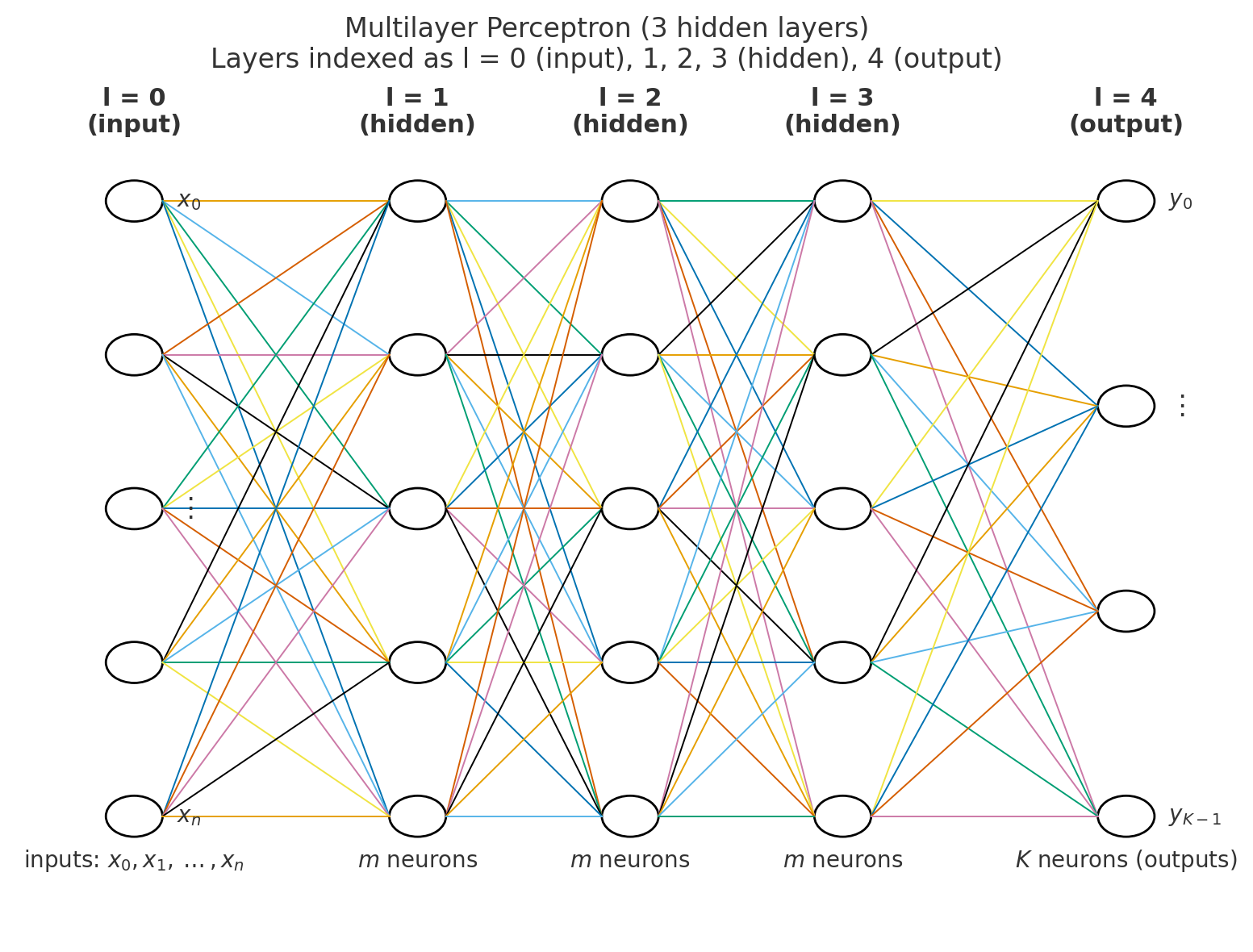
L + 1 layers, e.g. L = 4
Operations of a Neuron
like a biological neuron

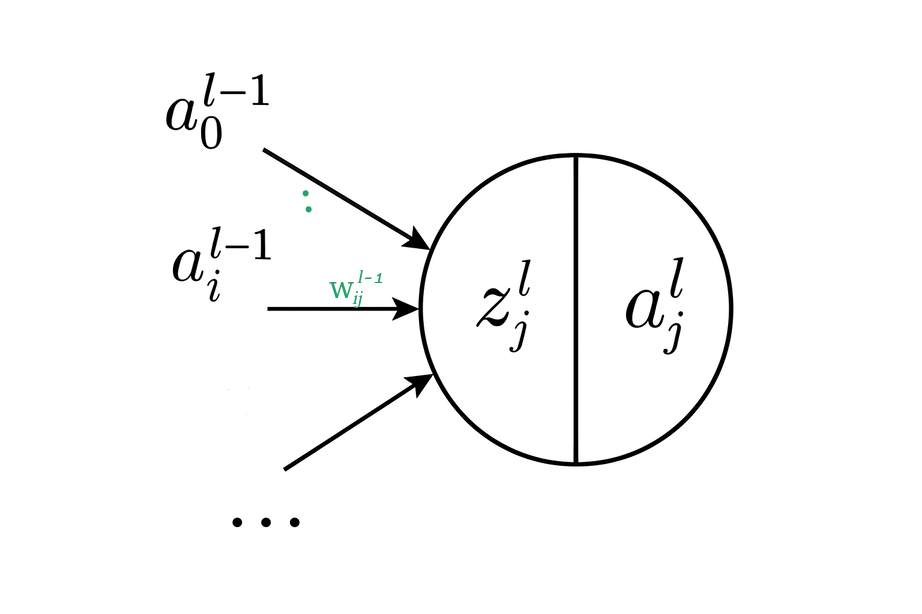
|

|
zi ~ logit

int n1; //number of inputs and bias
int m1; //number of hidden nodes and bias per layer
int K; //number of outputs
int L; //L+1 layers
int sizes[L+1]; //sizes of the layers: sizes[0] = n1, ..., sizes[L] = K
double w[L][N][N];
double z[L+1][N]; //linear sum of products of weights and 'inputs'
double a[L+1][N]; //value of neuron g(z[j])
double y[K]; //predicted output
//Forward propagation
double* MLP::forward(double x[])
{
for(int i = 0; i < n1; i++)
a[0][i] = z[0][i] = x[i];
for(int l = 0; l < L; l++) {
int left = sizes[l]; //size of left side layer
int right = sizes[l+1]; //size of right side layer
for(int j = 0; j < right; j++) {
z[l+1][j] = 0;
for(int i = 0; i < left; i++)
z[l+1][j] += w[l][i][j] * a[l][i];
if ( l < L-1 && j == 0 ) //hidden layer
a[l+1][j] = 1; //bias
else
a[l+1][j] = f( z[l+1][j] );
}
}
for (int k = 0; k < K; k++)
y[k] = a[L][k];
return y; //return output
}
|
Backward Propagation

|
|
//Backward propagation, yd is the desired output
void MLP::backward(double yd[], double x[])
{
double delta[L][N]; //hidden layers
//output delta
for (int k = 0; k < K; k++) {
double e = yd[k] - y[k]; //output layer error
delta[L-1][k] = e * fd(z[L][k]);
}
for(int l = L - 1; l >= 1; l--){
int left = sizes[l]; //size of left layer
int right = sizes[l+1]; //size of right layer
for (int j = 0; j < left; j++) {
delta[l-1][j] = 0;
for (int k = 0; k < right; k++)
delta[l-1][j] += w[l][j][k] * delta[l][k];
delta[l-1][j] *= fd( z[l][j] );
}
}
//Update weights
for (int l = 0; l < L; l++) {
int left = sizes[l];
int right = sizes[l+1];
for(int i = 0; i < left; i++)
for(int j = 0; j < right; j++)
w[l][i][j] += eta * delta[l][j] * a[l][i];
}
}
|