A ``Hello World" Example of Artificial Intelligence
in C/C++ and CUDA
Brief History of Artificial Intelligence (AI) Development
- Two main approaches in AI Development
- Based on statistics and optimization (SO)
- Based on neural networks (NN)
- The Early Beginnings (1940s - 1950s)
SO:- Pioneers like Ronald Fisher developed statistical methods for data analysis,
which could be used in machine learning.- Pioneers like George Dantzig (1947) developed Linear programming and
the simplex algorithm that laid the groundwork for solving optimization problems.- 1943: Warren McCulloch and Walter Pitts proposed a model of aritificial neurons,
laying the groundwork for neural networks.- 1950: Turing Test (by Alan Turing): a way to measure machine intelligence.
- Pioneers like Ronald Fisher developed statistical methods for data analysis,
- 1956: The term Artificial Intelligence was coined at the Dartmouth Conference.
- 1950-1970: Golden Years
SO:- Bayesian methods: The use of probability theory for inference and decision-making.
- Hidden Markov Models (HMMs): Used for speech recognition and time-series analysis.
- Frank Rosenblatt developed Perceptron, a simple neural network capable of learning.
The perceptron is a supervised learning algorithm.
It learns from labeled data to make predictions and adjusts its parameters to minimize errors.
While it is simple and limited in its capabilities, it laid the foundation for more advanced
supervised learning techniques in AI and machine learning. - The AI Winter (1970-1980)
In 1969, two MIT professors, Minsky and Papert published a book entitled Perceptrons:
Around this time, statistical methods and optimization continued to advance:
- Expectation-Maximization (EM) algorithm
- Support Vector Machines (SVMs)
- The Revival (1980s - 1990s)
- Statistical methods became dominate
- Neural Network research was a niche field.
backpropagation popularized (David E. Rumelhart, Geoffrey E. Hinton, and Ronald J. Williams in 1986)
- The Modern Era (2000s - present)
- In the early 2000s, large tech companies like Microsoft spent a huge amount of money on developing AI,
solely concentrating on utilizing statistical and optimization methods to advance.- The rise of big data and exponential increase in computational power brought together neural networks,
statistics, and optimization:- Deep Learning: Neural networks were revived using optimization techniques like
stochastic gradient descent (SGD) and backpropagation.- Probabilistic Programming: Frameworks like Pyro and Stan made it easier to build and infer
probabilistic models.- In late 2010s, the integration of optimization and statistics with neural network led to breakthroughs.
- In the early 2000s, large tech companies like Microsoft spent a huge amount of money on developing AI,
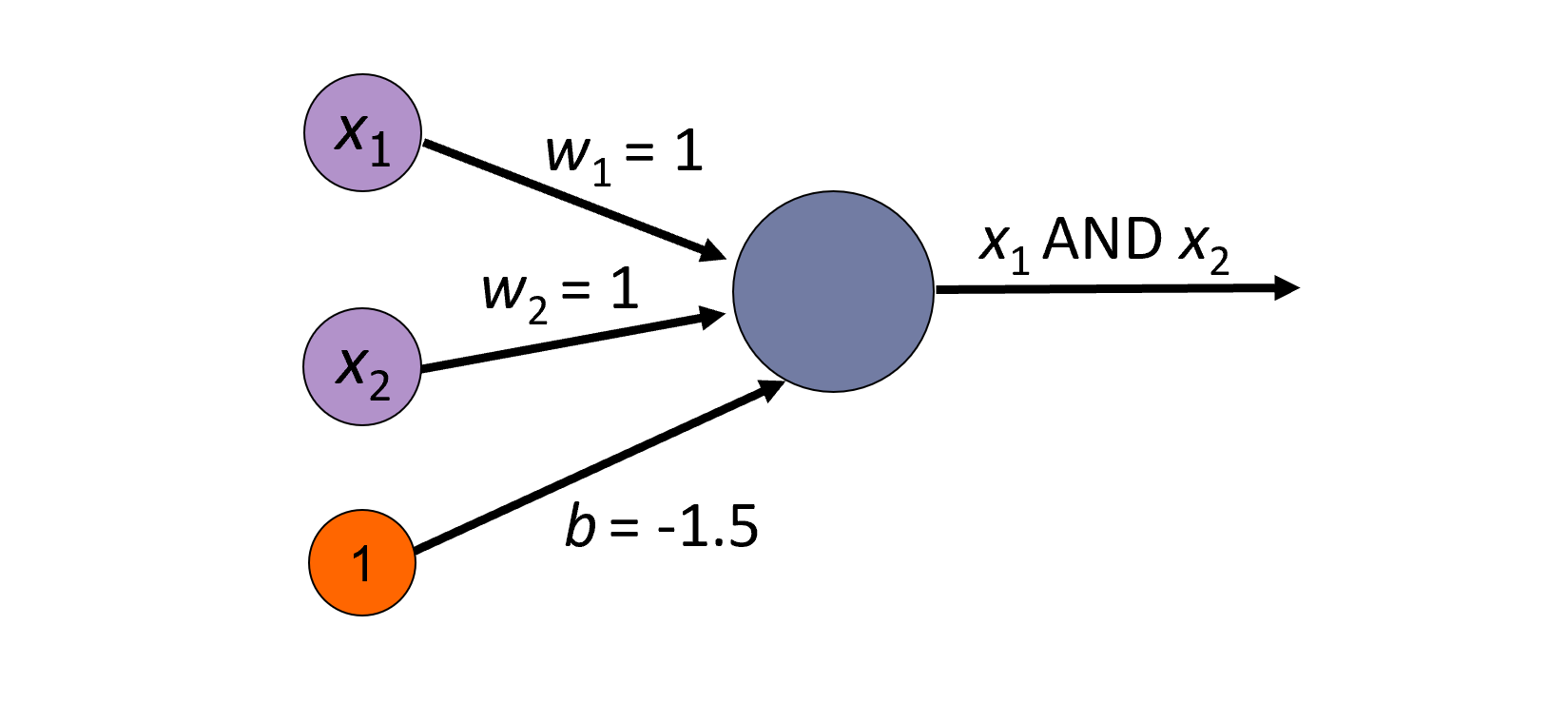
Perceptron
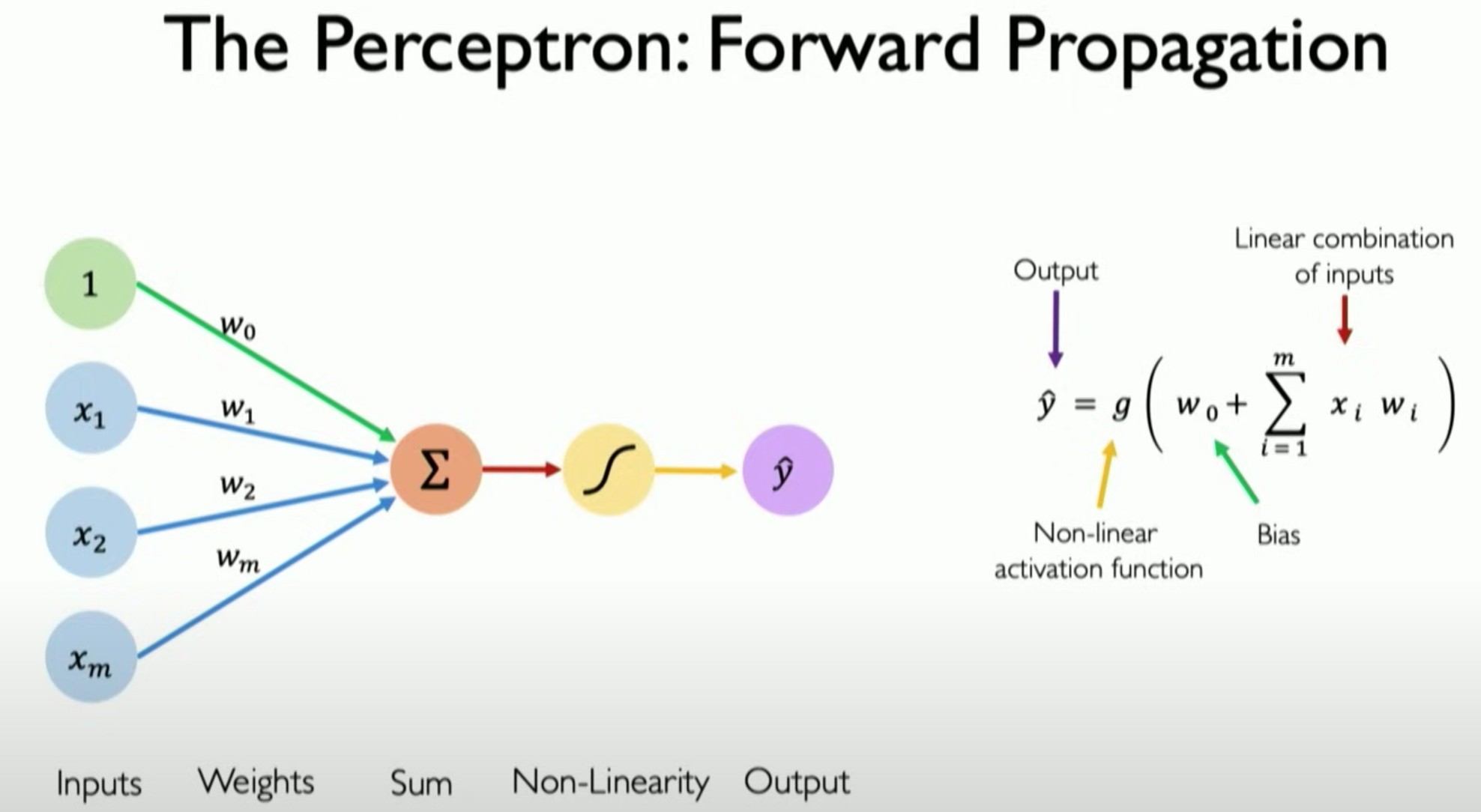
Activation function:
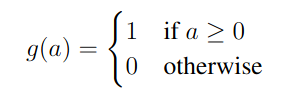
Learning in a perceptron: Initialization: Start with random weights and bias. Prediction: For each input, compute the output using the current weights and bias. with x0 = 1 Update: Update the weights and bias.
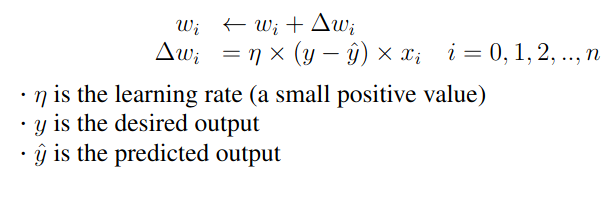
Can only learn linearly separable patterns.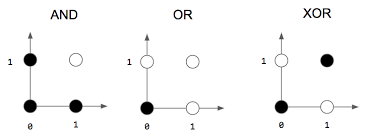
Able to distinguish data that are not linearly separable
Implementations
C/C++
//perceptron.cpp
#include <iostream>
using namespace std;
// Simple Perceptron class
class Perceptron
{
private:
double *w; //weights
double *x; //inputs
int n1; //n1=n+1, x[0], .... x[n], x[0] is 1
public:
Perceptron(int nx, double weights[])
{
n1 = nx;
w = new double[nx];
for(int i = 0; i < n1; i++)
w[i] = weights[i];
}
//Activation function (Step function)
int activation(double value)
{
return value >= 0 ? 1 : 0;
}
// Predicted output
int predictedOutput(double xi[])
{
x = xi;
double sum = 0;
for (int i = 0; i < n1; ++i)
sum += x[i] * w[i];
int y1 = activation(sum);
return y1;
}
// Train the perceptron
// eta = learning rate
// epochs = number of times of training
// numSamples = number of different input sets (x_data)
// y is target output
void train(double *x_data, double *y, double eta, int numSamples, int epochs)
{
double *x;
for (int m = 0; m < epochs; m++){
for (int k = 0; k < numSamples; k++) {
x = x_data + k * n1;
int y1 = predictedOutput( x );
int error = y[k] - y1;
// Update weights and bias
for (int i = 0; i < n1; i++) {
double dwi = eta * error * x[i];
w[i] = w[i] + dwi;
}
}
}
}
void printWeights()
{
cout << "\nPerceptron weights: ";
for(int i = 0; i < n1; i++)
cout << "\n w" << i <<": " << w[i];
}
~Perceptron()
{
delete w;
}
};
int main()
{
// Training data for AND gate, four sets of X
double inputs[] =
{
1, 0, 0, //x0=1, x1=0, x2=1
1, 0, 1, //x0=1, x1=0, x2=1
1, 1, 0, //x0=1, x1=1, x2=0
1, 1, 1 //x0=1, x1=1, x2=1
};
double y[] = {0, 0, 0, 1}; //target outputs (labels)
double w[] = {1, 1, 1};
string gates = " AND ";
//Construct a perception with a bias and 2 inputs
Perceptron perceptron(3, w);
// Train the perceptron
perceptron.train(inputs, y, 0.1, 4, 10);
// Test the perceptron
double x[3];
cout << "Testing Perceptron:" << endl;
x[0] = 1;
for (int i = 0; i < 4; i++) {
x[1] = i & 1;
x[2] = i >> 1;
int output = perceptron.predictedOutput(x);
cout << " " << x[2] << gates << x[1] << " = " << output << endl;
}
perceptron.printWeights();
cout << endl << "Hello, AI World!" << endl;
return 0;
}
|
CUDA Use one thread to update one weight in parallel.
//Activation function (Step function)
__device__ __host__ int activate(double value)
{
return value >= 0 ? 1 : 0;
}
// Predicted output
__device__ __host__ int predict(double x[], double w[], int n1)
{
double sum = 0;
for (int i = 0; i < n1; ++i)
sum += x[i] * w[i];
int y1 = activate(sum);
return y1;
}
__global__ void trainPerceptron(double *x_data, double *y, double *w, double eta, int n,
int numSamples, int epochs)
{
double *x;
int i = threadIdx.x;
for (int m = 0; m < epochs; m++){
for (int k = 0; k < numSamples; k++) {
x = x_data + k * n;
int y1 = predict(w, x, n);
int error = y[k] - y1;
// Update weights and bias
double dwi = eta * error * x[i];
w[i] = w[i] + dwi;
__syncthreads();
}
}
}
// Simple Perceptron class
class Perceptron
{
private:
double *w; //weights
double *x; //inputs
int n1; //n1=n+1, x[0], .... x[n], x[0] is 1
int wSize; //size of all weights in bytes
int numSamples; //number of different input sets (x_data)
double *d_w; //device memory to store weights
double *d_y; //device memory to sotre target outputs
double *d_x_data; //device memory to store samples data
public:
Perceptron(int nx, int num, double weights[], double *y, double inputs[])
{
n1 = nx;
numSamples = num;
wSize = n1 * sizeof(double);
int samplesSize = numSamples * wSize;
int outputsSize = numSamples * sizeof(double);
w = new double[n1];
for(int i = 0; i < n1; i++)
w[i] = weights[i];
cudaMalloc(&d_w, wSize);
cudaMalloc(&d_y, outputsSize);
cudaMalloc(&d_y, outputsSize);
cudaMalloc(&d_x_data, samplesSize);
cudaMemcpy(d_w, w, wSize, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, outputsSize, cudaMemcpyHostToDevice);
cudaMemcpy(d_x_data, inputs, samplesSize, cudaMemcpyHostToDevice);
}
//Activation function (Step function)
int activation(double value)
{
return activate(value);
}
// Predicted output
int predictedOutput(double xi[])
{
int y1 = predict(xi, w, n1);
return y1;
}
// Train the perceptron
// eta = learning rate
// epochs = number of times of training
// numSamples = number of different input sets (x_data)
// y is target output
void train(double eta, int epochs)
{
trainPerceptron<<<1, n1>>>(d_x_data, d_y, d_w, eta, n1, numSamples, epochs);
cudaDeviceSynchronize();
cudaMemcpy(w, d_w, wSize, cudaMemcpyDeviceToHost);
}
void printWeights()
{
cout << "\nPerceptron weights: ";
for(int i = 0; i < n1; i++)
cout << "\n w" << i <<": " << w[i];
}
~Perceptron()
{
delete w;
cudaFree(d_w);
cudaFree(d_y);
cudaFree(d_x_data);
}
};
int main()
{
....
//Construct a perception with a bias and 2 inputs
// 4 data sets
Perceptron perceptron(3, 4, w, y, inputs);
// Train the perceptron with eta = 0.1, and 10 epochs
perceptron.train(0.1, 10);
....
}
|